
README.md
@@ -4,7 +4,10 @@ [Course Content](https://rht-labs.github.io/enablement-docs/#/) ## Slides Use the [Open Innovation Labs reveal.js template](https://github.com/rht-labs/slides-template) to create new content. Add your slides and commit them to the `slides` dir Slides are currently only available on Red Hat's Google Drive (https://drive.google.com/open?id=1Rk0XAn2WjY-cVAhGbCNiL6EdiiS-hxbK). We are working on a solution to make this content more openly available. In the mean time, if you are unable to access the link above and would like to see some of the content, please contact the author. ## Exercises Exercises are created using [Docsify](https://docsify.js.org/#/). Write docs in Markdown and use [Docsify](https://github.com/QingWei-Li/docsify-cli) cli to serve them. Store your lab exercises in the `exercises/<lab-number>` dir. exercises/0-rogue-cluster/README.md
@@ -1,24 +1,105 @@ # Rogue Cluster > This section contains information needed when setting up the cluster for the learners. _____ > This section contains information needed when setting up the cluster, and a command line cheat sheet to help with completing exercises. <p class="tip"> NOTE - This section is a WIP and will evolve over time. </p> --- ## Cluster Requirements Learners will create 3 to 4 project namespaces running lightweight NodeJS app * 2 and a MongoDB in up to three of these namespace (dev, test, uat for example). The learners ci-cd namespace will house GitLab, Nexus and Jenkins as well as any slave pods used by jenkins. - Jenkins requires 5Gi of Persistent Storage and 4Gi of RAM - GitLab requires 2Gi of storage and 2Gi of RAM - PostgreSQL requires 1Gi of Storage and 512Mi of RAM - Redis requires 512Mi of storage - Nexus requires Learners will create 3 to 4 project namespaces running lightweight NodeJS app \* 2 and a MongoDB in up to three of these namespace (dev, test, uat for example). The learners ci-cd namespace will house GitLab, Nexus and Jenkins as well as any slave pods used by Jenkins. ## Cluster Access - Learners are in LDAP and can access cluster via `oc login` - Learners have access to LDAP bind credentials to be able to auth against gitlab ## User privileges - Learners will require privileges to run SCC containers ie GitLab - Jenkins requires 5Gi of Persistent Storage and 4Gi of RAM - GitLab requires 2Gi of storage and 2Gi of RAM - PostgreSQL requires 1Gi of Storage and 512Mi of RAM - Redis requires 512Mi of storage - Nexus requires 1Gi of storage. ## Cluster Access - Learners are in LDAP and can access cluster via `oc login` - Learners have access to LDAP bind credentials to be able to auth against GitLab ## User privileges - Learners deploying GitLab will require privileges to run SCC containers ## Labs Cheat Sheet This cheat sheet will give you some of the most useful commands and tips which you will need to complete the exercises. This should be most helpful to non-techies who need to get up to speed with command line techniques. If you come across anything else which would be useful during the enablement, write it on a post-it and add it to the real time retro or raise a pull request. - Changing Directory - `cd dir_name` Changes directory to `dir_name` within your current working directory - `cd /path/to/dir` Changes to the absolute location specified - `cd ..` Changes to the parent directory - `cd -` Changes to the previous diretory - Creating a blank file or directory - `touch file_name` Creates a blank file named `file_name` within the current directory - `mkdir dir_name` Creates a new directory named `dir_name` within the current directory - Listing files within current directory - `ls` prints a list of the files within your current directory - `ls -l` prints a list of the files within your current directory with more detail - Quickly see the contents of a file - `cat file_name` prints the contents of `file_name` to the console - Move or rename a file - `mv file_name dest_dir` will move the file from the current directory to `dest_dir` - `mv file_name new_name` will rename the file to `new_name` - Open a file - `open file_name` will open the file as though it had been double clicked in a standard user interface - Copy a file or directory - `cp file_name dest_dir` will create a copy of the file in the destination directory - `cp file_name copied_name` will create a copy of the file in the same directory and it shall be called `copied_name` - `cp -r dir_name dest_dir` will copy a directory to the destination location. Note the `-r` flag is necessary to copy the contents of the directory - Delete a file or directory - `rm file_name` will delete the file - `rm -rf dir_name` will delete the directory and all of its contents - Whatever you do, _do not_ run `sudo rm -rf /` - Search for a string within an input - `grep 'substring' file_name` will print all lines in the file which contain the string 'substring' - Place the output of one command into the input of another - `command1 | command2` will run command 1 then run command 2 with the input of the result of command 1. e.g. `ls | grep 'file'` will give you all files in the current directory which have 'file' in their name - Find out how to do things in the terminal - `man command1` will open the man pages (manual pages) for a particular command. - `man -k <search string>` will return a list of commands relevant to the search string you've entered. - If you want to know more about `man` try `man man` for more `man` on `man` information. - Run commands with root privileges - `sudo command1` will run a command with escalated privileges. This is safer than logging on as root user. ## Openshift 101 OpenShift, or OpenShift Container Platform (OCP) is Red Hat's container platform. It is used to run and manage containerised applications with the aim of accelerated application development and deployment. We shall be deploying all of our applications for this enablement on an OpenShift cluster. - What is a container? - A container is an isolated space within the operating system which is made to look like its own computer. Things within the container can only see what is in itself and cannot see anything about the computer it is really running on. Additionally multiple containers can be deployed with no interaction between one another meaning they will not coflict. - How do you control OpenShift? - There are two main ways of controlling OpenShift and the containers which reside within it. The first way is using the web interface; from here is it possible to use clicks to deploy an application. The easiest way to do this is direct from the source code using a Source-to-image (S2I) which comes out of the box with OpenShift. It is also possible (and encouraged) to use the command line interface, using the `oc` command, to control OCP. The other option is to use Ansible to set the cluster to a defined standard, as set out in an Ansible playbook. ## Ansible 101 Ansible is a tool which automates software provisioning, configuration management, and application deployment. - How to run an Ansible playbook - `ansible-playbook file.yml -i inventory_dir/` will run the Ansible playbook defined in file.yml (playbooks are defined in YAML format). The inventory directory will contain all of the information about what will be deployed. In the enablement we will use Ansible extensively, but the structure will be given to you to make this easier. exercises/1-the-manual-menace/README.md
@@ -1,16 +1,16 @@ # The Manual Menace > In this exercise learners will use Ansible to drive automated provisioning of Projects in Openshift, Git, Jenkins and Nexus. > In this exercise learners will use Ansible to drive automated provisioning of Projects in OpenShift, Git, Jenkins and Nexus.  ## Exercise Intro In this exercise we will use automation tooling to create Project namespaces for our `CI/CD` tooling along with the `dev` and `test` namespaces for our deployments to live. We do this to manually using the OpenShift CLI; but as we go from cluster to cluster or project to project Dev and Ops teams often find themselves having to redo these tasks again and again. Configuring our cluster using code; we can easily store this in Git and repeat the process again and again. By minimising the time taken to do these repetitive tasks we can accelerate our ability to deliver value to our customers; working on the hard problems they face. In this exercise we will use automation tooling to create Project namespaces for our `CI/CD` tooling along with the `dev` and `test` namespaces for our deployments to live. We do this manually using the OpenShift CLI; but as we go from cluster to cluster or project to project Dev and Ops teams often find themselves having to redo these tasks again and again. Configuring our cluster using code; we can easily store this in Git and repeat the process again and again. By minimising the time taken to do these repetitive tasks we can accelerate our ability to deliver value to our customers; working on the hard problems they face. This exercise uses Ansible to drive the creation of the cluster content. In particular; we'll use a play book called the `OpenShift Applier`. Once the project namespace have been created; we will add some tools to support CI/CD such as Jenkins, Git and Nexus. These tools will be needed by later lessons to automate the build and deploy of our apps. Again; we will use OpenShift Templates and drive their creation in the cluster using Ansible. To prove things are working, finally we'll delete all our content and re-apply the inventory to re-create our clusters content. This exercise uses Ansible to drive the creation of the cluster content. In particular; we'll use a play book called the `OpenShift Applier`. Once the project namespace have been created; we will add some tools to support CI/CD such as Jenkins, Git and Nexus. These tools will be needed by later lessons to automate the build and deploy of our apps. Again; we will use OpenShift Templates and drive their creation in the cluster using Ansible. To prove things are working, finally we'll delete all our content and re-apply the inventory to re-create our cluster's content. #### Why is config-as-code important? #### Why is config-as-code important? * Assurance - Prevents unwanted config changes from people making arbitrary changes to environments. No more Snowflake servers! * Traceability - Commiting config as code means a user has approved and changes can be tracked. * Traceability - Committing config as code means a user has approved and changes can be tracked. * Phoenix Server - Burn it all to the ground and bring it back; exactly the way it was! _____ @@ -30,33 +30,32 @@ * [Ansible](https://www.ansible.com/) - IT Automation tool used to provision and manage state of cloud and physical infrastructure. * [OpenShift Applier](https://github.com/redhat-cop/openshift-applier) - used to apply OpenShift objects to an OpenShift Cluster. ## Big Picture > The Big Picture is our emerging architecture; starting with an empty cluser we populate it with projects and some ci/cd tooling. > The Big Picture is our emerging architecture; starting with an empty cluster we populate it with projects and some ci/cd tooling.   _____ ## 10,000 Ft View > This exercise is aimed at the creation of the tooling that will be used to support the rest of the Exercises. The highlevel goal is to create a collection of project namespaces and populate them with Git, Jenkins & Nexus. > This exercise is aimed at the creation of the tooling that will be used to support the rest of the Exercises. The high-level goal is to create a collection of project namespaces and populate them with Git, Jenkins & Nexus. If you're feeling confident and don't want to follow the step-by-step guide these highlevel instructions should provide a challenge for you: If you're feeling confident and don't want to follow the step-by-step guide these high-level instructions should provide a challenge for you: 2. Clone the repo `https://github.com/rht-labs/enablement-ci-cd` which contains the scaffold of the project. Ensure you get all remote branches. 1. Clone the repo `https://github.com/rht-labs/enablement-ci-cd` which contains the scaffold of the project. Ensure you get all remote branches. 2. Create `<your-name>-ci-cd`, `<your-name>-dev` and `<your-name>-test` project namespaces using the inventory and run them with the OpenShift Applier to populate the cluster 2. Use the templates provided to create build of the jenkins-s2i. The templates are in `exercise1/jenkins-s2i` 3. Use the templates provided to create build of the jenkins-s2i. The templates are in `exercise1/jenkins-s2i` 2. Use the templates provided to create build and deployment configs in `<your-name>-ci-cd` for. Templates are on a branch called `exercise1/git-nexus` && `exercise1/jenkins`: 4. Use the templates provided to create build and deployment configs in `<your-name>-ci-cd` for. Templates are on a branch called `exercise1/git-nexus` && `exercise1/jenkins`: * Nexus * GitLab * Jenkins (using an s2i to pre-configure jenkins) * Jenkins (using an s2i to pre-configure Jenkins) 2. Commit your `enablement-ci-cd` repository to the GitLab Instance you've created 5. Commit your `enablement-ci-cd` repository to the GitLab Instance you've created 2. Burn it all down and re-apply your inventory proving config-as-code works. 6. Burn it all down and re-apply your inventory proving config-as-code works. ## Step by Step Instructions > This is a structured guide with references to exact filenames and explanations. @@ -106,7 +105,7 @@ * `requirements.yml` is a manifest which contains the ansible modules needed to run the playbook * `apply.yml` is a playbook that sets up some variables and runs the OpenShift Applier role. 3. Open the `apply.yml` file in the root of the project. Update the namespace variables by replacing the `<YOUR_NAME>` with your name or initials. Don't use uppercase or special characters. For example; my name is Dónal so I've created: 3. Open the `apply.yml` file in the root of the project. Update the namespace variables by replacing the `<YOUR_NAME>` with your name or initials. Don't use uppercase or special characters. For example; my name is Dónal so I've created: ```yaml hosts: "{{ target }}" vars: @@ -121,11 +120,11 @@ 3. Open the `inventory/host_vars/projects-and-policies.yml` file; you should see some variables setup already to create the `<YOUR_NAME>-ci-cd` namespace. This object is passed to the OpenShift Applier to call the `templates/project-requests.yml` template with the `params/project-requests-ci-cd` parameters. We will add some additional content here but first let's explore the parameters and the template 3. Open the `params/project-requests-ci-cd` and replace the `<YOUR_NAME>` with your name to create the correstponding projects in the cluster. 3. Open the `params/project-requests-ci-cd` and replace the `<YOUR_NAME>` with your name to create the corresponding projects in the cluster.  3. Let's add two more param files to pass to our template to be able to create a `dev` and `test` project. * Create another two params files `params/project-requests-dev` & `params/project-requests-test`. On the terminal run 3. Let's add two more params files to pass to our template to be able to create a `dev` and `test` project. * Create another two params files `params/project-requests-dev` & `params/project-requests-test`. On the terminal run ```bash touch params/project-requests-dev params/project-requests-test ``` @@ -162,7 +161,7 @@ ansible-galaxy install -r requirements.yml --roles-path=roles ``` 3. Apply the inventory by logging into OpenShift on the terminal and running the playbook as follows (<CLUSTER_URL> should be replaced with the one you've been sent as shown below). Accept any insecure connection warning 👍: 3. Apply the inventory by logging into OpenShift on the terminal and running the playbook as follows (<CLUSTER_URL> should be replaced with the one you've been sent as shown below). Accept any insecure connection warning 👍: ```bash oc login https://console.lader.rht-labs.com ``` @@ -171,9 +170,9 @@ ``` where the `-e target=bootstrap` is passing an additional variable specifying that we run the `bootstrap` inventory 3. Once successful you should see an output similar to this (Cow's not included):  3. Once successful you should see an output similar to this (Cows not included):  3. You can check to see the projects have been created successfully by running 3. You can check to see the projects have been created successfully by running ```bash oc projects ``` @@ -188,7 +187,7 @@ ``` The template contains all the things needed to setup a persistent nexus server, exposing a service and route while also creating the persistent volume needed. Have a read through the template; at the bottom you'll see a collection of parameters we will pass to the template. 4. Add some parameters for running the template by creating a new file in the `params` directory. 4. Add some parameters for running the template by creating a new file in the `params` directory. ```bash touch params/nexus ``` @@ -199,7 +198,7 @@ MEMORY_LIMIT=1Gi ``` 4. Create a new object in the inventory variables `inventory/host_vars/ci-cd-tooling.yml` called `ci-cd-tooling` and populate it's `content` is as follows 4. Create a new object in the inventory variables `inventory/host_vars/ci-cd-tooling.yml` called `ci-cd-tooling` and populate its `content` is as follows ```yaml --- @@ -216,7 +215,7 @@ ```  4. Run the OpenShift applier, specifying the tag `nexus` to speed up it's execution (`-e target=tools` is to run the other inventory). 4. Run the OpenShift applier, specifying the tag `nexus` to speed up its execution (`-e target=tools` is to run the other inventory). ```bash ansible-playbook apply.yml -e target=tools \ -i inventory/ \ @@ -227,7 +226,7 @@ ### Part 3 - GitLab #### 3a - GitLab install #### 3a - GitLab install <p class="tip"> NOTE - This section may already have been completed for you, please check with your tutor. If this is the case, skip to section 3b "Commit CI/CD" below to add your code to GitLab. </p> @@ -235,7 +234,7 @@ 4. Now let's do the same thing for GitLab to get it up and running. Checkout the template and params provided by running ```bash git checkout exercise1/git-nexus templates/gitlab.yml params/gitlab ``` ``` Explore the template; it contains the PVC, buildConfig and services. The DeploymentConfig is made up of these apps - Redis (3.2.3) - PostgreSQL (9.4) @@ -263,8 +262,8 @@ * `<BIND_USER_PASSWORD>` is the password used when querying the LDAP * `<YOUR_DOMAIN>` is the domain the LDAP is hosted on * `<LDAP_HOST>` is fqdn of the LDAP server * `<LDAP_DESCRIPTION>` is the description to be used on the sign-in header for GitLab eg "Name LDAP Login" * `<GITLAB_ROOT_USER_PASSWORD>` is the root user for GOD access on the GitLab instance eg password123 * `<LDAP_DESCRIPTION>` is the description to be used on the sign-in header for GitLab e.g. "Name LDAP Login" * `<GITLAB_ROOT_USER_PASSWORD>` is the root user for GOD access on the GitLab instance e.g. password123 * `<GITLAB_URL>` is the endpoint for gitlab. It will take the form `gitlab-<YOUR_NAME>-ci-cd.apps.<ENV_ID>.<YOUR_DOMAIN>.com` 4. Create another object in the inventory `inventory/host_vars/ci-cd-tooling.yml` file to run the build & deploy of this template. Add the following and update the `namespace:` accordingly @@ -277,7 +276,7 @@ - gitlab ``` 4. Run the OpenShift applier, specifying the tag `gitlab` to speed up it's execution. 4. Run the OpenShift applier, specifying the tag `gitlab` to speed up its execution. ```bash ansible-playbook apply.yml -e target=tools \ -i inventory/ \ @@ -288,16 +287,16 @@ #### 3b - Commit CI/CD 4. Navigate to gitlab (if you have just skipped straight to this step; ask your tutor for the URL). You can login using your cluster credentials using the LDAP tab 4. Navigate to GitLab (if you have just skipped straight to this step; ask your tutor for the URL). You can login using your cluster credentials using the LDAP tab  4. Once logged in create a new project called `enablement-ci-cd` and mark it as internal. Once created; copy out the `git url` for use on the next step.  <p class="tip"> Note - we would not normally make the project under your name but create an group and add the project there on residency but for simplicity of the exercise we'll do that here Note - we would not normally make the project under your name but create a group and add the project there on residency but for simplicity of the exercise we'll do that here </p> 4. If you have not used Git before; you may need to tell Git who you are and what your email is before we commit. Run the following commands, substitution your email and "Your Name". If you've done this before move on to the next step. 4. If you have not used Git before; you may need to tell Git who you are and what your email is before we commit. Run the following commands, substituting your email and "Your Name". If you've done this before move on to the next step. ```bash git config --global user.email "yourname@mail.com" ``` @@ -305,7 +304,7 @@ git config --global user.name "Your Name" ``` 4. Commit your local project to this new remote by first removing the existing origin (github) where the ansible project was cloned from in the first steps. Remember to substitute `<GIT_URL>` accordingly with the one created for your `enablement-ci-cd` repository a moment ago. 4. Commit your local project to this new remote by first removing the existing origin (github) where the Ansible project was cloned from in the first steps. Remember to substitute `<GIT_URL>` accordingly with the one created for your `enablement-ci-cd` repository a moment ago. ```bash git remote set-url origin <GIT_URL> ``` @@ -327,7 +326,7 @@ git checkout exercise1/mongodb params/mongodb templates/mongodb.yml ``` 4. Open `enablement-ci-cd` in your favourite editor. Edit the `inventory/host_vars/ci-cd-tooling.yml` to include a new object for our mongodb as shown below. This item can be added below the jenkins slave in the `ci-cd-tooling` section. 4. Open `enablement-ci-cd` in your favourite editor. Edit the `inventory/host_vars/ci-cd-tooling.yml` to include a new object for our mongodb as shown below. This item can be added below the Jenkins slave in the `ci-cd-tooling` section. ```yaml - name: "jenkins-mongodb" namespace: "{{ ci_cd_namespace }}" @@ -349,7 +348,7 @@ git push ``` 4. Apply this change as done previously using ansible. The deployment can be validated by going to your `<YOUR_NAME>-ci-cd` namespace and checking if it is there! 4. Apply this change as done previously using Ansible. The deployment can be validated by going to your `<YOUR_NAME>-ci-cd` namespace and checking if it is there! ```bash ansible-playbook apply.yml -e target=tools \ -i inventory/ \ @@ -366,7 +365,7 @@ ```bash git checkout exercise1/jenkins templates/jenkins.yml ``` The Jenkins template is essentially the standard persistent jenkins one with OpenShift. The Jenkins template is essentially the standard persistent Jenkins one with OpenShift. 5. As before; create a new set of params by creating a `params/jenkins` file and adding some overrides to the template and updating the `<YOUR_NAME>` value accordingly. ``` @@ -377,7 +376,7 @@ JENKINS_OPTS=--sessionTimeout=720 ``` 5. Add a `jenkins` variable to the ansible inventory underneath the jenkins-mongo (and git if you have it) in `inventory/host_vars/ci-cd-tooling.yml`. 5. Add a `jenkins` variable to the Ansible inventory underneath the jenkins-mongo (and git if you have it) in `inventory/host_vars/ci-cd-tooling.yml`. ```yaml - name: "jenkins" namespace: "{{ ci_cd_namespace }}" @@ -388,11 +387,11 @@ ``` This configuration, if applied now, will create the deployment configuration needed for Jenkins but the `${NAMESPACE}:${JENKINS_IMAGE_STREAM_TAG}` in the template won't exist yet. 5. To create this image we will take the supported OpenShift Jenkins Image and bake into it some extra configuration using an [s2i](https://github.com/openshift/source-to-image) builder image. More information on Jenkins s2i is found on the [openshift/jenkins](https://github.com/openshift/jenkins#installing-using-s2i-build) github page. To create an s2i configuration for jenkins, check out the pre-canned configuration source in the `enablement-ci-cd` repo 5. To create this image we will take the supported OpenShift Jenkins Image and bake into it some extra configuration using an [s2i](https://github.com/openshift/source-to-image) builder image. More information on Jenkins s2i is found on the [openshift/jenkins](https://github.com/openshift/jenkins#installing-using-s2i-build) GitHub page. To create an s2i configuration for Jenkins, check out the pre-canned configuration source in the `enablement-ci-cd` repo ```bash git checkout exercise1/jenkins-s2i jenkins-s2i ``` The structure of the jenkins s2i config is The structure of the Jenkins s2i config is ``` jenkins-s2i ├── README.md @@ -412,21 +411,21 @@ * `build-failure-analyzer.xml` is config for the plugin to read the logs and look for key items based on a Regex. More on this in later lessons. * `init.groovy` contains a collection of settings jenkins configures itself with when launching 5. Let's add a plugin for Jenkins to be started with, [green-balls](https://plugins.jenkins.io/greenballs). This simply changes the default `SUCCESS` status of Jenkins from Blue to Green. Append the `jenkins-s2i/plugins.txt` file with 5. Let's add a plugin for Jenkins to be started with, [green-balls](https://plugins.jenkins.io/greenballs). This simply changes the default `SUCCESS` status of Jenkins from Blue to Green. Append the `jenkins-s2i/plugins.txt` file with ```txt greenballs:1.15 ``` ```  Why does Jenkins have Blue Balls? More can be found [on reddit](https://www.reddit.com/r/programming/comments/4lu6q8/why_does_jenkins_have_blue_balls/) or the [jenkins blog](https://jenkins.io/blog/2012/03/13/why-does-jenkins-have-blue-balls/) 5. Before building and deploying the Jenkins s2i; add git credentials to it. These will be used by Jenkins to access the Git Repositories where our apps will be stored. We want Jenkins to be able to push tags to it so write access is required. There are a few ways we can do this; either adding them to the `template/jenkins.yml` as environment Variables and then including them in the `params/jenkins` file. We could also create a token in GitLab and use it as the source secret in the jenkins template. But for simplicity just replace the `<USERNAME>` && `<PASSWORD>` in the `jenkins-s2i/configuration/init.groovy` with your ldap credentials as seen below. This init file gets run when Jenkins launches and will setup the credentials for use in our Jobs in the next exercises 5. Before building and deploying the Jenkins s2i; add git credentials to it. These will be used by Jenkins to access the Git Repositories where our apps will be stored. We want Jenkins to be able to push tags to it so write access is required. There are a few ways we can do this; either adding them to the `template/jenkins.yml` as environment Variables and then including them in the `params/jenkins` file. We could also create a token in GitLab and use it as the source secret in the Jenkins template. But for simplicity just replace the `<USERNAME>` && `<PASSWORD>` in the `jenkins-s2i/configuration/init.groovy` with your LDAP credentials as seen below. This init file gets run when Jenkins launches and will setup the credentials for use in our Jobs in the next exercises ```groovy gitUsername = System.getenv("GIT_USERNAME") ?: "<USERNAME>" gitPassword = System.getenv("GIT_PASSWORD") ?: "<PASSWORD>" ``` <p class="tip"> Note in a residency we would not use your GitCredentials for pushing and pulling from Git, A service user would be created for this. Note in a residency we would not use your GitCredentials for pushing and pulling from Git, a service user would be created for this. </p> 5. Checkout the params and the templates for the `jenkins-s2i` @@ -434,7 +433,7 @@ git checkout exercise1/jenkins-s2i params/jenkins-s2i templates/jenkins-s2i.yml ``` 5. Open `params/jenkins-s2i` and add the following content; replacing variables as appropriate. 5. Open `params/jenkins-s2i` and add the following content; replacing variables as appropriate. ``` SOURCE_REPOSITORY_URL=<GIT_URL> NAME=jenkins @@ -443,8 +442,8 @@ SOURCE_REPOSITORY_USERNAME=<YOUR_LDAP_USERNAME> SOURCE_REPOSITORY_PASSWORD=<YOUR_LDAP_PASSWORD> ``` where * `<GIT_URL>` is the full path clone path of the repo where this project is stored (including the https && .git) where * `<GIT_URL>` is the full clone path of the repo where this project is stored (including the https && .git) * `<YOUR_NAME>` is the prefix for your `-ci-cd` project. * Explore some of the other parameters in `templates/jenkins-s2i.yml` * `<YOUR_LDAP_USERNAME>` is the username builder pod will use to login and clone the repo with @@ -453,7 +452,7 @@ Note in a residency we would not use your GitCredentials for pushing and pulling from Git, A service user would be created or a token generated. </p> 5. Create a new object `ci-cd-builds` in the ansible `inventory/host_vars/ci-cd-tooling.yml` to drive the s2i build configuration. 5. Create a new object `ci-cd-builds` in the Ansible `inventory/host_vars/ci-cd-tooling.yml` to drive the s2i build configuration. ```yaml - object: ci-cd-builds content: @@ -476,7 +475,7 @@ git push ``` 5. In order for Jenkins to be able to run `npm` builds and installs we must configure a `jenkins-build-slave` for Jenkins to use. This slave will be dynamically provisioned when we run a build. It needs to have NodeJS and npm installed in it. These slaves can take a time to build themselves so to speed up we have placed the slave within openshift and you can use the following commands to be able to use them in your project. 5. In order for Jenkins to be able to run `npm` builds and installs we must configure a `jenkins-build-slave` for Jenkins to use. This slave will be dynamically provisioned when we run a build. It needs to have NodeJS and npm installed in it. These slaves can take a time to build themselves so to speed up we have placed the slave within OpenShift and you can use the following commands to be able to use them in your project. ```bash oc project <YOUR_NAME>-ci-cd ``` @@ -498,9 +497,9 @@ 5. This will trigger a build of the s2i and when it's complete it will add an imagestream of `<YOUR_NAME>-ci-cd/jenkins:latest` to the project. The Deployment config should kick in and deploy the image once it arrives. You can follow the build of the s2i by going to the OpenShift console's project  5. When the Jenkins deployment has completed; login (using your openshift credentials) and accept the role permissions. You should now see a fairly empty Jenkins with just the seed job 5. When the Jenkins deployment has completed; login (using your OpenShift credentials) and accept the role permissions. You should now see a fairly empty Jenkins with just the seed job ### Part 6 - Jenkins Hello World ### Part 6 - Jenkins Hello World > _To test things are working end-to-end; create a hello world job that doesn't do much but proves we can pull code from git and that our balls are green._ 6. Log in to Jenkins and hit `New Item` . @@ -511,10 +510,10 @@ 6. On the build tab add an Execute Shell step and fill it with `echo "Hello World"` . 6. Run the build and we should see if pass succesfully and with Green Balls!  6. Run the build and we should see if pass successfully and with Green Balls!  ### Part 7 - Live, Die, Repeat > _In this section you will proove the infra as code is working by deleting your Cluster Content and recreating it all_ > _In this section you will prove the infra as code is working by deleting your Cluster Content and recreating it all_ 7. Commit your code to the new repo in GitLab ```bash exercises/2-attack-of-the-pipelines/README.md
@@ -5,9 +5,9 @@  ## Exercise Intro This lesson is focused on creating a pipeline for our application. What is a pipeline? A pipeline is a series of steps or stages that takes our code from source to a deployed application. There can be many stages to a pipeline but a simple flow is to run a `build > bake > deploy`. Usually the first stage is trigger by something like a git commit. There could be many steps in each of these stages; such as compiling code, running tests and linting. All of these are done to try and drive up code quality and give more assurance that what is deployed is behaving as expected. In the exercise we will create Jenkins pipeline by configuring it through the UI, this will create an un-gated pathway to production This lesson is focused on creating a pipeline for our application. What is a pipeline? A pipeline is a series of steps or stages that takes our code from source to a deployed application. There can be many stages to a pipeline but a simple flow is to run a `build > bake > deploy`. Usually the first stage is triggered by something like a git commit. There could be many steps in each of these stages; such as compiling code, running tests and linting. All of these are done to try and drive up code quality and give more assurance that what is deployed is behaving as expected. In the exercise we will create Jenkins pipeline by configuring it through the UI, this will create an un-gated pathway to production First we will explore the sample application and get it running locally. The sample app is a `todolist` app - the `Hello World` app of the modern day. First we will explore the sample application and get it running locally. The sample app is a `todolist` app - the `Hello World` app of the modern day. #### Why create pipelines * Assurance - drive up code quality and remove the need for dedicated deployment / release management teams @@ -37,18 +37,20 @@ 1. [VueJS](https://vuejs.org/) - Vue (pronounced /vjuː/, like view) is a progressive framework for building user interfaces. It is designed from the ground up to be incrementally adoptable, and can easily scale between a library and a framework depending on different use cases. It consists of an approachable core library that focuses on the view layer only, and an ecosystem of supporting libraries that helps you tackle complexity in large Single-Page Applications. ## Big Picture > From the previous exercise; we created some supporting tooling needed by our app/ > From the previous exercise; we created some supporting tooling needed by our app. Now we will introduce our Sample App and create a pipeline for it  _____ ## 10,000 Ft View > _This lab requires users to take the sample TODO app and create a build pipeline in Jenkins by clicking your way to success ending up with an app deployed to each of the namespaces created previously_ 2. Import the projects into your gitlab instance. See README of each for build instructions 2. Import the projects into your gitlab instance. See the README of each for build instructions 2. Deploy a `MongoDB` using the provided template to all project namespace. 2. Create 2 pipline with three stages (`build`, `bake`, `deploy`) in jenkins for `develop` & `master` branches on the `todolist-fe` such that: 2. Create 2 pipelines with three stages (`build`, `bake`, `deploy`) in Jenkins for `develop` & `master` branches on the `todolist-fe` such that: * a `Build` job is responsible for compiling and packaging our code: 1. Checkout from source code (`develop` for `<yourname>-dev` & `master` for `<yourname>-test`) 2. Install node dependencies and run a build / package @@ -58,8 +60,8 @@ 5. Trigger the `bake` job with the `${BUILD_TAG}` param * a `Bake` job should take the package and put it in a Linux Container 1. Take an input of the previous jobs `${BUILD_TAG}` ie `${JOB_NAME}.${BUILD_NUMBER}`. 2. Checkout the binary from Nexus and unzip it's contents 3. Run an oc start-build of the App's BuildConfig and tag it's imagestream with the provided `${BUILD_TAG}` 2. Checkout the binary from Nexus and unzip its contents 3. Run an oc start-build of the App's BuildConfig and tag its imagestream with the provided `${BUILD_TAG}` 4. Trigger a deploy job using the parameter `${BUILD_TAG}` * a `deploy` job should roll out the changes by updating the image tag in the DC: 1. Take an input of the `${BUILD_TAG}` @@ -96,7 +98,7 @@ git checkout develop ``` 2. Open up Gitlab and login. Create a new project (internal) in GitLab called `todolist-fe` to host your clone of the project and copy it's remote address.  2. Open up Gitlab and login. Create a new project (internal) in GitLab called `todolist-fe` to host your clone of the project and copy its remote address.  2. In your local clone of the `todolist-fe`, remove the origin and add the GitLab origin by replacing `<YOUR_GIT_LAB_PROJECT>`. Push your app to GitLab ```bash @@ -111,12 +113,12 @@ node -v npm -v ``` <p class="tip" > <p class="tip" > NOTE - If you are missing these dependencies; install them with ease using the [Node Version Manager](https://github.com/creationix/nvm) </p>  2. The `todolist-fe` has a package.json at the root of the project, this defines some configuration for the app including it's dependencies, dev dependencies, scripts and other configuration. Install the apps dependencies 2. The `todolist-fe` has a package.json at the root of the project, this defines some configuration for the app including its dependencies, dev dependencies, scripts and other configuration. Install the app's dependencies ```bash npm install ``` @@ -176,7 +178,7 @@ * `./src/store` is the `vuex` files for managing application state and backend connectivity * `./src/views` is the view containers; which are responsible for loading components and managing their interactions. * the `./src/router.js` controls routing logic. In our case the app only has one real endpoint. * `./src/scss` contains custom SCSS used in the application. * `./src/scss` contains custom SCSS used in the application. * `./*.js` is mostly config files for running and managing the app and the tests 2. To prepare Nexus to host the binaries created by the frontend and backend builds we need to run a prepare-nexus script. Before we do this we need to export some variables and change `<YOUR_NAME>` accordingly in the below commands. @@ -212,7 +214,7 @@ git checkout develop ``` 2. On GitLab; create a new project (internal) called `todolist-api` to host your clone of the project and copy it's remote address as you did for the previous repositories. 2. On GitLab; create a new project (internal) called `todolist-api` to host your clone of the project and copy its remote address as you did for the previous repositories. 2. In your local clone of the `todolist-api`, remove the origin and add the GitLab origin by replacing `<YOUR_GIT_LAB_PROJECT>`. Push your app to GitLab ```bash @@ -260,10 +262,10 @@ where the following are the important things: * `./server` is the main collection of files needed by the app. The entrypoint is the `app.js` * `./node_modules` is where the dependencies are stored * `./server/api` is where the api's controller, data model & unit test are stored. * `./server/api` is where the api's controller, data model & unit test are stored. * `./server/mocks` is a mock server used for when there is no DB access * `./server/config` stores our Express JS config, header information and other middleware. * `./server/config/environment` stores enviromnent specific config; such as connectivity to backend services like MongoDB. * `./server/config/environment` stores environment specific config; such as connectivity to backend services like MongoDB. * `./tasks` is a collection of additional `Grunt` tasks which will be used in later exercises * `Grunt` is a taskrunner for use with Node.JS projects * `package.json` contains the dependency list and a lot of very helpful scripts for managing the app lifecycle @@ -284,7 +286,7 @@ }, ``` 2. To run the application; start a new instance of the MongoDB by running the following. This will pull a mongodb image from Dockerhub and then start it for our API to connect to. 2. To run the application; start a new instance of MongoDB by running the following. This will pull a mongodb image from Dockerhub and then start it for our API to connect to. ```bash npm run mongo ``` @@ -320,10 +322,10 @@ 2. Now let's check out `todolist-fe` app by reloading the browser. We should now see our dummy front end data is replaced by the backend seed data. Adding new todos will add them in the backend, these will persist when the page is refreshed.  ### Part 2 - Add configs to cluster ### Part 2 - Add configs to cluster > _In this exercise; we will use the OpenShift Applier to drive the creation of cluster content required by the app such as MongoDB and the Apps Build / Deploy Config_ 4. On your terminal navigate to the root of the `todolist-fe` application. The app contains a hidden folder called `.openshift-applier`. Move into this `.openshift-applier` directory and you should see a familiar looking directory structure for an ansible playbook. 4. On your terminal navigate to the root of the `todolist-fe` application. The app contains a hidden folder called `.openshift-applier`. Move into this `.openshift-applier` directory and you should see a familiar looking directory structure for an Ansible playbook. ``` .openshift-applier ├── README.md @@ -344,19 +346,19 @@ └── todolist-fe-deploy.yml ``` with the following * the `apply.yml` file is the entrypoint. * the `apply.yml` file is the entrypoint. * the `inventory` contains the objects to populate the cluster with. * the `params` contains the variables we'll apply to the `templates` * the `templates` required by the app. These include the Build, Deploy configs as well as the services, health checks, and other app definitions. 4. There are a few updates to these manifests we need to make before applying the cluster content. In the `apply.yml` update the namespace `<YOUR_NAME>` variables accordingly. 4. There are a few updates to these manifests we need to make before applying the cluster content. In the `apply.yml` update the namespace `<YOUR_NAME>` variables accordingly. ```yaml ci_cd_namespace: donal-ci-cd dev_namespace: donal-dev test_namespace: donal-test ``` 4. In the `params` folder update the `dev` and `test` files with the correct `<YOUR_NAME>` as you've done above. Example for the `dev` file: 4. In the `params` folder update the `dev` and `test` files with the correct `<YOUR_NAME>` as you've done above. Example for the `dev` file: ```bash PIPELINES_NAMESPACE=donal-ci-cd NAME=todolist-fe @@ -428,7 +430,7 @@ 4. Check `<YOUR_NAME>-dev` to see the deployment configs are in place  ### Part 3 - Build > Bake > Deploy ### Part 3 - Build > Bake > Deploy > _In this exercise; we take what we have working locally and get it working in OpenShift_ This exercise will involve creating three stages (or items) in our pipeline, each of these is detailed below at a very high level. Move on to the next step to begin implementation. @@ -441,8 +443,8 @@ 5. Trigger the `bake` job with the `${BUILD_TAG}` param * a *bake* job should take the package and put it in a Linux Container 1. Take an input of the previous jobs `${BUILD_TAG}` ie `${JOB_NAME}.${BUILD_NUMBER}`. 2. Checkout the binary from Nexus and unzip it's contents 3. Run an oc start-build of the App's BuildConfig and tag it's imagestream with the provided `${BUILD_TAG}` 2. Checkout the binary from Nexus and unzip its contents 3. Run an oc start-build of the App's BuildConfig and tag its imagestream with the provided `${BUILD_TAG}` 4. Trigger a deploy job using the parameter `${BUILD_TAG}` * a *deploy* job should roll out the changes by updating the image tag in the DC: 1. Take an input of the `${BUILD_TAG}` @@ -455,9 +457,9 @@ 5. With the BuildConfig and DeployConfig in place for both our apps (`*-fe` & `*-api`) from previous steps; Log into Jenkins and create a `New Item`. This is just jenkins speak for a new job configuration.  5. Name this job `dev-todolist-fe-build` and select `Freestyle Job`. All our jobs will take the form of `<ENV>-<APP_NAME>-<JOB_PURPOSE>`.  5. Name this job `dev-todolist-fe-build` and select `Freestyle Project`. All our jobs will take the form of `<ENV>-<APP_NAME>-<JOB_PURPOSE>`.  5. The page that loads is the Job Configuration page and it can be returned to at anytime from Jenkins. Let's start configuring our job. To conserve space; we will make sure Jenkins only keeps the last builds artifacts. Tick the `Discard old builds` checkbox, then `Advanced` and set `Max # of builds to keep with artifacts` to 1 as indicated below 5. The page that loads is the Job Configuration page and it can be returned to at anytime from Jenkins. Let's start configuring our job. To conserve space; we will make sure Jenkins only keeps the last build's artifacts. Tick the `Discard old builds` checkbox, then `Advanced` and set `Max # of builds to keep with artifacts` to 1 as indicated below  5. Our NodeJS build needs to be run on the `jenkins-slave-npm` we bought in in the previous chapter. Specify this in the box labelled `Restrict where this project can be run`  @@ -480,7 +482,7 @@ 5. On the Post-build Actions; Add another post-build action from the dropdown called `Git Publisher`. This is useful for tying the git check-in to the feature in your tracking tool to the built product. * Tick the box `Push Only If Build Succeeds` * Add the Tag to push of * Add the Tag to push of ```bash ${JOB_NAME}.${BUILD_NUMBER} ``` @@ -492,10 +494,10 @@ * Check `Create New Tag` and set `Target remote name` to `origin`  5. Finally; add the trigger for the next job in the pipeline. This is to trigger the bake job with the current build tag. Add another post-build action from the dropdown called `Trigger parameterized build on other projects`. * Set the project to build to be `dev-todolist-fe-bake` * Set the condition to be `Stable or unstable but not failed`. * Click Add Parameters dropdown and select Predefined parameters. 5. Finally; add the trigger for the next job in the pipeline. This is to trigger the bake job with the current build tag. Add another post-build action from the dropdown called `Trigger parameterized build on other projects`. * Set the project to build to be `dev-todolist-fe-bake` * Set the condition to be `Stable or unstable but not failed`. * Click Add Parameters dropdown and select Predefined parameters. * In the box, insert our BUILD_TAG as follows ```bash BUILD_TAG=${JOB_NAME}.${BUILD_NUMBER} @@ -515,7 +517,7 @@ * Add string parameter type * set the Name to `BUILD_TAG`. This will be available to the job as an Enviroment Variable. * You can set `dev-todolist-fe-build.` as the default value for ease when triggering manually. * The description is not required but a handy one for reference would be `${JOB_NAME}.${BUILD_NUMBER} of previous build eg dev-todolist-fe-build.1232` * The description is not required but a handy one for reference would be `${JOB_NAME}.${BUILD_NUMBER} of previous build e.g. dev-todolist-fe-build.1232` <p class="tip"> NOTE - Don't forget to include the `.` after `dev-todolist-fe-build` in the Default Value box. </p> @@ -575,7 +577,7 @@ ```  5. When a deployment has completed; OpenShift can verify it's success. Add another step by clicking the `Add build Step` on the Build tab then `Verify OpenShift Deployment` including the following: 5. When a deployment has completed; OpenShift can verify its success. Add another step by clicking the `Add build Step` on the Build tab then `Verify OpenShift Deployment` including the following: * Set the Project to your `<YOUR_NAME>-dev` * Set the DeploymentConfig to your app's name `todolist-fe` * Set the replica count to `1` @@ -590,7 +592,7 @@ 5. Update `<YOUR_NAME>` accordingly with the route where the Todo List API will live when it is deployed. The correct full URL can also be found on the OpenShift Console; if you copy it from there remember to append `/api/todos` to the URL. For example:  5. Repeat this for `src/config/test.js` file. If you copy the URL from the previous step; change `dev` to `test`. 5. Repeat this for `src/config/test.js` file. If you copy the URL from the previous step; change `dev` to `test`. For example:  @@ -608,7 +610,7 @@ 5. Back on Jenkins; We can tie all the jobs in the pipeline together into a nice single view using the Build Pipeline view. Back on the Jenkins home screen Click the + beside the all tab on the top.  5. On the view that loads; Give the new view a sensible name like `dev-todolist-fe-pipeline` and select Build Pipeline 5. On the view that loads; Give the new view a sensible name like `dev-todolist-fe-pipeline` and select Build Pipeline View  5. Set the Pipeline Flow's Inital Job to `dev-todolist-fe-build` and save. @@ -630,7 +632,7 @@ NOTE - This section is optional! Git webhooks are useful but not needed for Enablement completion. </p> 7. In order to allow GitLab trigger Jenkins (because of the OpenShift Auth Plugin), we need to allow the `Anonymous` user trigger builds. Head to your Jenkins Dashboard and click on `Manage Jenkins` on the left hand side. Then scroll down and click `Configure Global Security`. Alternatively, type in `https://jenkins-<YOUR_NAME>-ci-cd.apps.some.domain.com/configureSecurity/` . You should see a screen like so: 7. In order to allow GitLab to trigger Jenkins (because of the OpenShift Auth Plugin), we need to allow the `Anonymous` user triggered builds. Head to your Jenkins Dashboard and click on `Manage Jenkins` on the left hand side. Then scroll down and click `Configure Global Security`. Alternatively, type in `https://jenkins-<YOUR_NAME>-ci-cd.apps.some.domain.com/configureSecurity/` . You should see a screen like so:  7. Scroll down to the `Authorization` section and allow `Anonymous` to create jobs. Do this by navigating through the matrix of checkboxes and check `Build` and `Cancel` under the Job heading. Leave all other user behaviour as is. Anonymous is the user that GitLab will act as so this allows the WebHook to trigger builds. (The screenshot has been cropped to bring Job further to the left.) Hit `Save` or `Apply`. exercises/3-revenge-of-the-automated-testing/README.md
@@ -15,13 +15,13 @@ The TDD cycle can be illustrated with the following diagram;  ### The TDD Cycle ### The TDD Cycle 1. `Write a test` - In TDD a new feature begins by writing a test. Write a test that clearly defines a function or one that provides an improvement to an existing function. It's important the developer clearly understands the features specification and requirements, or the feature could be wrong from the get-go. In TDD a new feature begins by writing a test. Write a test that clearly defines a function or one that provides an improvement to an existing function. It's important the developer clearly understands the feature's specification and requirements, or the feature could be wrong from the get-go. 2. `Test Fails` - When a test is first implemented it is expected to fail. This failure validates the test is working correctly as the feature is yet to be implemented. When a test is first implemented it is expected to fail. This failure validates the test is working correctly as the feature is yet to be implemented. 3. `Write code to make test pass` - This step involves implementing the feature to pass the failed test. Code written at this stage may be inelegant and still pass the test, however this is acceptable as TDD is a recursive cycle which includes code refactoring. @@ -36,7 +36,7 @@ Starting with another new test, the cycle is then repeated to push forward the functionality. The size of the steps should always be small, with as few as 1 to 10 edits between each test run. If new code does not rapidly satisfy a new test, or other tests fail unexpectedly, the programmer should undo or revert in preference to excessive debugging. ### Testing Bananalogy Explanation of Mocha and js test syntax through Bananalogy! Imagine for a moment; we're not building software but creating a bowl of fruit. To create a `Bunch of Bananas` component for our fruit bowl we could start with our tests as shown below. Explanation of Mocha and JS test syntax through Bananalogy! Imagine for a moment; we're not building software but creating a bowl of fruit. To create a `Bunch of Bananas` component for our fruit bowl we could start with our tests as shown below.  * `describe` is used to group tests together. The string `"a bunch of ripe bananas"` is for human reading and allows you to identify tests. * `it` is a statement that contains a test. It should contain an assertion such as `expect` or `should`. It follows the syntax of `describe` where the string passed in identifies the statement. @@ -60,20 +60,21 @@ 1. [Vue Test Utils](https://vue-test-utils.vuejs.org/en/) - Vue Test Utils is the official unit testing utility library for Vue.js. 1. [Nightwatch.js](http://nightwatchjs.org/) - Nightwatch.js is an easy to use Node.js based End-to-End (E2E) testing solution for browser based apps and websites. It uses the powerful W3C WebDriver API to perform commands and assertions on DOM elements. 1. [Mocha](https://mochajs.org/) - Mocha is a feature-rich JavaScript test framework running on Node.js and in the browser, making asynchronous testing simple and fun. Mocha tests run serially, allowing for flexible and accurate reporting, while mapping uncaught exceptions to the correct test cases. Hosted on GitHub. 1. [Sinon](http://sinonjs.org/) - Standalone test spies, stubs and mocks for JavaScript. 1. [Sinon](http://sinonjs.org/) - Standalone test spies, stubs and mocks for JavaScript. Works with any unit testing framework. ## Big Picture > From the previous exercise; we created a simple pipeline. We will now flesh it out with some testing to add gates to our pathway to production. This exercise begins cluster containing blah blah  --- ## 10,000 Ft View > The goal of this exercise is to add a new component to the application using TDD to create and validate it's behaviour. The User story we have been given is as follows: > The goal of this exercise is to add a new component to the application using TDD to create and validate its behaviour. The User story we have been given is as follows: *As a doer I want to mark todos as important so that I can keep track of and complete high prirority todos first* *As a doer I want to mark todos as important so that I can keep track of and complete high priority todos first* _Acceptance Criteria_ - [ ] should be doable with a single click @@ -94,14 +95,14 @@ #### 1a - FE Unit tests > In this exercise we will execute our test for the front end locally. Once verified we will add them to Jenkins. 2. Before linking our automated testing to the pipeline we'll first ensure the tests run locally. Change to the `todolist-fe` directory and run `test`. 1. Before linking our automated testing to the pipeline we'll first ensure the tests run locally. Change to the `todolist-fe` directory and run `test`. ```bash cd todolist-fe ``` ```bash npm run test ``` <p class="tip" > <p class="tip" > `test` is an alias used that runs `vue-cli-service test` from the scripts object in `package.json` </p>  @@ -111,7 +112,7 @@ 2. You should see an output similar to the following. The above command has run a test suite for every `*.spec.js` file. The table generated in the terminal shows the code coverage. We're going to be focusing on the unit tests for now.  2. Repeat the same process for `todolist-api` and verify that all the tests run. If you have an ExpressJS server already running from previous exercise; you should kill it before running the tests. The `mocha` test suite will launch a dev server for running the tests. There are 2 Api test files: `todolist-api/server/api/todo/todo.spec.js` & `todolist-api/server/mocks/mock-routes.spec.js` for our API and the Mocks server. 2. Repeat the same process for `todolist-api` and verify that all the tests run. If you have an ExpressJS server already running from previous exercise; you should kill it before running the tests. The `mocha` test suite will launch a dev server for running the tests. There are 2 API test files: `todolist-api/server/api/todo/todo.spec.js` & `todolist-api/server/mocks/mock-routes.spec.js` for our API and the Mocks server. ```bash cd todolist-api ``` @@ -119,7 +120,7 @@ npm run test ``` 2. Navigate to your instance of jenkins at `https://jenkins-<YOUR_NAME>-ci-cd.apps.lader.rht-labs.com/`. 2. Navigate to your instance of Jenkins at `https://jenkins-<YOUR_NAME>-ci-cd.apps.lader.rht-labs.com/`. Click on `dev-todolist-fe-build` and then click the `configure` button on the left-hand side.  @@ -151,7 +152,7 @@ git push ``` 2. Rerun the `dev-todolist-fe-build` job. It should have failed and not run any other jobs. 2. Rerun the `dev-todolist-fe-build` job. It should have failed and not run any other jobs.  2. You can examine the test results on the jobs home page. Drill down into the tests to see which failed and other useful stats @@ -252,7 +253,7 @@ - `res.body.should.be.instanceof(Array);` is the actual test call - `done();` tells the test runner that `mocha` has finished execution. This is needed as the http calls are asynchronous. 3. With this knowledge; let's implement our test for the `important` flag. We expect the front end to introduce a new property on each `todo` that gets passed to the backend called `important`. The API will need to handle this new property and pass it into the mongodb. Let's begin implementing this functionality by writing our test case. Navigate to the `PUT /api/todos` section of the `server/api/todo/todo.spec.js` test file (which should be at the bottom) 3. With this knowledge; let's implement our test for the `important` flag. We expect the front end to introduce a new property on each `todo` that gets passed to the backend called `important`. The API will need to handle this new property and pass it into the mongodb. Let's begin implementing this functionality by writing our test case. Navigate to the `PUT /api/todos` section of the `server/api/todo/todo.spec.js` test file (which should be at the bottom)  3. Before writing our test; let's first make sure all the existing tests are passing. @@ -303,7 +304,7 @@ }); ``` 3. Next we need to update the `server/config/seed.js` file so that the pre-generated todos have an important propety. Add `important: true` below `completed: *` for each object. Don't forget to add a comma at the end of the `completed: *` line. 3. Next we need to update the `server/config/seed.js` file so that the pre-generated todos have an important property. Add `important: true` below `completed: *` for each object. Don't forget to add a comma at the end of the `completed: *` line.  3. With your changes to the Database schema updated; re-run your tests. @@ -340,13 +341,13 @@ ``` #### 2b - Create todolist-fe tests > Using [Jest](https://facebook.github.io/jest/) as our test runner and the `vue-test-utils` library for managing our vue components; we will now write some tests for front end functionality to persist our important-flag. The changes required to the front end are quite large but we will use TDD to create our test first, then implement the functionality. > Using [Jest](https://facebook.github.io/jest/) as our test runner and the `vue-test-utils` library for managing our vue components; we will now write some tests for front end functionality to persist our important-flag. The changes required to the front end are quite large but we will use TDD to create our test first, then implement the functionality. Our TodoList App uses `vuex` to manage the state of the apps' todos and `axios` HTTP library to connect to the backend. `Vuex` is an opinionated framework for managing application state and has some key design features you will need to know to continue with the exercise. Our TodoList App uses `vuex` to manage the state of the app's todos and `axios` HTTP library to connect to the backend. `Vuex` is an opinionated framework for managing application state and has some key design features you will need to know to continue with the exercise. In `vuex` the application state is managed by a `store`. The `store` houses all the todos we have retrieved from the backend as well as the `getter` methods for our array of `todos`. In order to make changes to the store, we could call the store directly and update each todo item but as earlier said; vuex is an opinionated module with it's own way of updating the store. It is bad practice to call the store directly. In `vuex` the application state is managed by a `store`. The `store` houses all the todos we have retrieved from the backend as well as the `getter` methods for our array of `todos`. In order to make changes to the store, we could call the store directly and update each todo item but as earlier said; vuex is an opinionated module with its own way of updating the store. It is bad practice to call the store directly. There are two parts of the lifecycle to updating the store, the `actions` & `mutations`. When the user clicks a todo to mark it as complete; the `actions` are called. An action could involve a call to the backend or some pre-processing of the data. Once this is done, the change is committed to the store by calling the `mutation` function. A store should only ever be manipulated through a mutation function. Calling the mutation will then update the todo object in the apps local store for rendering in the view. There are two parts of the lifecycle to updating the store, the `actions` & `mutations`. When the user clicks a todo to mark it as complete; the `actions` are called. An action could involve a call to the backend or some pre-processing of the data. Once this is done, the change is committed to the store by calling the `mutation` function. A store should only ever be manipulated through a mutation function. Calling the mutation will then update the todo object in the app's local store for rendering in the view. For example; when marking a todo as done in the UI, the following flow occurs * The `TodoItem.vue` calls the `markTodoDone()` function which dispatches an event to the store. @@ -366,7 +367,7 @@ git push -u origin feature/important-flag ``` 3. Let's get our tests running by executing a `--watch` on our tests. This will keep re-running our tests everytime there is a file change. It is hany to have this running in a new terminal session. 3. Let's get our tests running by executing a `--watch` on our tests. This will keep re-running our tests everytime there is a file change. It is handy to have this running in a new terminal session. ```bash npm run test -- --watch ``` @@ -377,7 +378,7 @@ 3. There are three places we will add new tests to validate our function behaves as expected against the acceptance criteria from the Feature Story supplied to us. We will need to write tests for our `TodoItem.vue` to handle having a red flag and that it is clickable. Our app is going to need to persist the changes in the backend so we'll want to make changes to our `actions.js` and `mutations.js` to keep the api and local copy of the store in sync. Let's start with our `TodoItem.vue` component. Open the `tests/unit/vue-components/TodoItem.spec.js` file. This has been templated with some example test to correspond with our A/Cs for speed of doing the exercise. Find the describe block for our important flag tests. It is setup already with a `beforeEach()` hook for test setup.  3. Each of our test cases has it's skeleton in place already for example the `TodoItem.vue` component takes a property of `todos` when rendering. This setup is already done for each of our tests so all we have to do is fill in our assertions. 3. Each of our test cases has its skeleton in place already for example the `TodoItem.vue` component takes a property of `todos` when rendering. This setup is already done for each of our tests so all we have to do is fill in our assertions.  3. Let's implement the first test `it("should render a button with important flag"`. This test will assert if the button is present on the page and it contains the `.important-flag` CSS class. To implement this; add the `expect` statement as follows below the `// TODO - test goes here!` comment. @@ -413,9 +414,9 @@ }); ``` 3. Finally, we want to make the flag clickable and for it to call a function to update the state. The final test in the `TodoItem.spec.js` we want to create should simulate this behaviour. Implement the `it("call makImportant when clicked", () ` test by first simulating the click of our important-flag and asserting the function `markImportant()` to write is executed. 3. Finally, we want to make the flag clickable and for it to call a function to update the state. The final test in the `TodoItem.spec.js` we want to create should simulate this behaviour. Implement the `it("call markImportant when clicked", () ` test by first simulating the click of our important-flag and asserting the function `markImportant()` to write is executed. ```javascript it("call makImportant when clicked", () => { it("call markImportant when clicked", () => { const wrapper = mount(TodoItem, { methods, propsData: { todoItem: importantTodo } @@ -432,7 +433,7 @@ * The `<script></script>` contains the JavaScript of our component and is essentially the logic for our component. It defines things like `properties`, `methods` and other `components` * The `<style></style>` contains the encapsulated CSS of our component 3. Underneath the `</md-list-item>` tag, let's add a new md-button. Add a `.important-flag` class on the `md-button` and put the svg of the flag provided inside it. 3. Underneath the `</md-list-item>` tag, let's add a new md-button. Add an `.important-flag` class on the `md-button` and put the svg of the flag provided inside it. ```html </md-list-item> <!-- TODO - SVG for use in Exercise3 --> @@ -448,7 +449,7 @@ </md-button> ``` 3. More tests should now be passing. Let's wire the click of the flag to an event in Javascript. In the methods section of the `<script></script>` tags in the Vue file, implement the `markImportant()`. We want to wire this to the action to updateTodo, just like we have in the `markCompleted()` call above it. We also need to pass and additional property to this method call `important` 3. More tests should now be passing. Let's wire the click of the flag to an event in Javascript. In the methods section of the `<script></script>` tags in the Vue file, implement the `markImportant()`. We want to wire this to the action to updateTodo, just like we have in the `markCompleted()` call above it. We also need to pass an additional property to this method called `important` ```javascript markImportant() { // TODO - FILL THIS OUT IN THE EXERCISE @@ -457,7 +458,7 @@ }, ``` 3. Let's connect the click button in the DOM to the Javascript function we've just created. In the template, add a click handler to the md-button to call the function `markImportant()` by adding ` @click="markImportant()"` to the `<md-button> tag 3. Let's connect the click button in the DOM to the Javascript function we've just created. In the template, add a click handler to the md-button to call the function `markImportant()` by adding ` @click="markImportant()"` to the `<md-button>` tag ```html <!-- TODO - SVG for use in Exercise3 --> <md-button class="important-flag" @click="markImportant()"> @@ -469,7 +470,7 @@  3. The previously failing tests should have started to pass now. With this work done, let's commit our code. On the terminal, run 3. The previously failing tests should have started to pass now. With this work done, let's commit our code. On the terminal, run ```bash git add . ``` @@ -507,7 +508,7 @@ } ``` 3. Finally, let's implement the `mutation` for our feature. Again, starting with the tests..... Open the `tests/unit/javascript/mutations.spec.js` to find our skeleton tests at the bottom of the file. Our mutation method is responsible for toggling the todo's `important` property between `true` and `false`. Let's implement the tests for this functionality by setting important to be true and calling the method expecting the inverse. Then let's set it to false and call the method expecting the inverse. Add the expectations below the `// TODO - test goes here!` comment as done previously. 3. Finally, let's implement the `mutation` for our feature. Again, starting with the tests... Open the `tests/unit/javascript/mutations.spec.js` to find our skeleton tests at the bottom of the file. Our mutation method is responsible for toggling the todo's `important` property between `true` and `false`. Let's implement the tests for this functionality by setting important to be true and calling the method expecting the inverse. Then let's set it to false and call the method expecting the inverse. Add the expectations below the `// TODO - test goes here!` comment as done previously. ```javascript it("it should MARK_TODO_IMPORTANT as false", () => { state.todos = importantTodos; @@ -566,7 +567,40 @@ #### 2c - Create todolist e2e tests 3. TODO !! > Using [Nightwatch.js](http://nightwatchjs.org/) We will write a reasonably simple e2e test to test the functionality of the feature we just implemented. 3. Firstly we need to create an e2e spec test file in the correct place. ```bash touch tests/e2e/specs/importantFlag.js ``` 3. Open this new file in your code editor and set out the initial blank template for an e2e test as below:  3. Now get the test to access the todos page and wait for it to load. The url can be taken from `process.env.VUE_DEV_SERVER_URL`  3. Now click the clear all button and then enter a value in the textbox to create a new item. We clear all first to ensure we start with a fresh list. We now do our first assertion: that a 'important flag' exists (the button to set important), and also that a red flag does not exist. You will quickly find there is no way to reference the clear all button. We will therefore have to go to `src/components/XofYItems.vue` and add `id="clear-all"` to the clear all button.   3. We should now get nightwatch to click the flag and check whether the flag has turned red.  3. At this point we should have a working e2e test. We can run this by using `npm run e2e`. When satisfied we can push up these changes. ```bash git add . ``` ```bash git commit -m "Implementing e2e tests" ``` ```bash git push ``` --- @@ -587,4 +621,4 @@ - [Intro](https://docs.google.com/presentation/d/18W0GoBTwRGpgbOyHf2ZnL_OIWU_DvsoR14H0_t5jisA) - [Wrap-up](https://docs.google.com/presentation/d/1uIYHC57POSaVD6XNZGhdetABiSnlP1TztYTgglMP-DA) - [All Material](https://drive.google.com/drive/folders/1xVaQukmwwmyJSDN0zOkghZX7yb-0freT) - [All Material](https://drive.google.com/drive/folders/1xVaQukmwwmyJSDN0zOkghZX7yb-0freT) exercises/4-an-enslaved-hope/README.md
@@ -1,20 +1,20 @@ # An Enslaved Hope > In this exercise we'll break free from the chains of point'n'click Jenkins by introducing pipeline as code in the form of `Jenkinsfile`. Following this we will introduce some new Jenkins slaves that will be used in later exercises. > In this exercise we'll break free from the chains of point'n'click Jenkins by introducing pipeline as code in the form of `Jenkinsfile`. Following this we will introduce some new Jenkins slaves that will be used in later exercises.  There are a number of ways pipeline as code can be achieved in Jenkins. * The Job DSL Plugin - this is a slightly older but very functional DSL mechanism to create reusable pipelines. Create a `groovy` file to run Jenkins Domain Specific Language to create jobs, functions and other items. In Jenkins; you then can execute this file which will build all of the config.xml files needed for each Job. * The Scripted Pipeline - The scripted pipeline introduced the Jenkinsfile and the ability for developers to write their jenkins setup as groovy code. A repo with a Jenkinsfile in it's root can be pointed to by Jenkins and it will automatically build out each of the stages described within. The scripted pipeline is ultimately Groovy at it's core. * The Job DSL Plugin - this is a slightly older but very functional DSL mechanism to create reusable pipelines. Create a `groovy` file to run Jenkins Domain Specific Language to create jobs, functions and other items. In Jenkins; you then can execute this file which will build all of the config.xml files needed for each Job. * The Scripted Pipeline - The scripted pipeline introduced the Jenkinsfile and the ability for developers to write their Jenkins setup as groovy code. A repo with a Jenkinsfile in its root can be pointed to by Jenkins and it will automatically build out each of the stages described within. The scripted pipeline is ultimately Groovy at its core. * The Declarative Pipeline - This approach looks to simplify and opinionate what you can do and when you can do it in a pipeline. It does this by giving you top level `block` which define sections, directives and steps. The declarative syntax is not run as groovy but you can execute groovy inside script blocks. The advantage of it over scripted is validation of the config and lighter approach with requirement to understand all of the `groovy` syntax _____ ## Learning Outcomes As a learner you will be able to - Use a Jenkinsfile to create a declarative pipeline to build, bake and deploy the Todolist App - Identify the differences between scripted, declarative and DSL pipelines - Use a Jenkinsfile to create a declarative pipeline to build, bake and deploy the Todolist App - Identify the differences between scripted, declarative and DSL pipelines - Create Jenkins slave nodes for use in builds in future exercises ## Tools and Frameworks @@ -27,19 +27,21 @@ 1. [Arachni Crawler](http://www.arachni-scanner.com/) - Arachni is a feature-full, modular, high-performance Ruby framework aimed towards helping penetration testers and administrators evaluate the security of modern web applications. It is free, with its source code public and available for review. It is versatile enough to cover a great deal of use cases, ranging from a simple command line scanner utility, to a global high performance grid of scanners, to a Ruby library allowing for scripted audits, to a multi-user multi-scan web collaboration platform. In addition, its simple REST API makes integration a cinch. ## Big Picture This exercise begins cluster containing blah blah > From the previous exercise; we gated our pipeline. Now we will add a pipeline-as-code in the form of the Jenkinfile and re-use it on the Backend too.  _____ ## 10,000 Ft View > The goal of this exercise is to move to using the Jenkinsfile in the todolist-api and todolist-fe projects. Additionally we will create new slaves for use in the next exercise. 2. On Jenkins; create a multibranch pipeline project to scan the GitLab endpoint for each app. Use the Jenkinsfile provided to run the stages. Replace the `<YOUR_NAME>` with appropriate variable. 2. On Jenkins; create a multibranch pipeline project to scan the GitLab endpoint for each app. Use the Jenkinsfile provided to run the stages. Replace `<YOUR_NAME>` with the appropriate variable. 2. Create two new Jenkins slaves for the `OWASP ZAP` scanner and the `Arachni` WebCrawler ## Step by Step Instructions > This is a fairly structured guide with references to exact filenames and sections of text to be added. > This is a fairly structured guide with references to exact filenames and sections of text to be added. ### Part 1 - The Jenkinsfile > _In this exercise we'll replace the Pipeline we created in Exercise 2 with a Jenkinsfile approach_ @@ -49,17 +51,17 @@ git checkout feature/jenkinsfile ``` 2. Open up your `todolist-api` application in your favourite editor and move to the `Jenkinsfile` in the root of the project. The highlevel structure of the file is shown collapsed below. 2. Open up your `todolist-api` application in your favourite editor and move to the `Jenkinsfile` in the root of the project. The high-level structure of the file is shown collapsed below.  Some of the key things to note: * `pipeline {}` is how all declarative jenkins pipelines begin. * `pipeline {}` is how all declarative Jenkins pipelines begin. * `environment {}` defines environment variables to be used across all build stages * `options {}` contains specific Job specs you want to run globally across the jobs e.g. setting the terminal colour * `stage {}` all jobs must have one stage. This is the logical part of the build that will be executed e.g. `bake-image` * `steps {}` each `stage` has one or more steps involved. These could be execute shell or git checkout etc. * `agent {}` specifies the node the build should be run on eg `jenkins-slave-npm` * `post {}` hook is used to specify the post-build-actions. Jenkins declarative provides very useful callbacks for `success`, `failure` and `always` which are useful for controlling the job flow * `when {}` is used for flow control. It can be used at stage level and be used to stop pipeline entering that stage. eg when branch is master; deploy to `test` environment. * `agent {}` specifies the node the build should be run on e.g. `jenkins-slave-npm` * `post {}` hook is used to specify the post-build-actions. Jenkins declarative pipeline syntax provides very useful callbacks for `success`, `failure` and `always` which are useful for controlling the job flow * `when {}` is used for flow control. It can be used at the stage level and be used to stop pipeline entering that stage. e.g. when branch is master; deploy to `test` environment. 2. The Jenkinsfile is mostly complete to do all the testing etc that was done in previous exercises. Some minor changes will be needed to orchestrate namespaces. Find and replace all instances of `<YOUR_NAME>` in the Jenkinsfile. Update the `<GIT_USERNAME>` to the one you login to the cluster with; this variable is used in the namespace of your git projects when checking out code etc. Ensure the `GITLAB_DOMAIN` matches your git host. ```groovy @@ -100,10 +102,10 @@ 2. Fill in the Git settings with your `todolist-api` GitLab url and set the credentials as you've done before. `https://gitlab.apps.lader.rht-labs.com/<YOUR_NAME>/todolist-api.git`  2. Set the `Scan Multibranch Pipeline Triggers` to be periodic and the interval to 1 minute. This will poll the gitlab instance for new branches or change sets to build. 2. Set the `Scan Multibranch Pipeline Triggers` to be periodic and the interval to 1 minute. This will poll the GitLab instance for new branches or change sets to build.  2. Save the Job configuration to run the intial scan. The log will show scans for `master` and `develop` branch which have no `Jenkinsfile` so are skipped. The resulting view will show the `feature/jenkinsfile` job corresponding the only branch that currently has one. The build should run automatically. 2. Save the Job configuration to run the intial scan. The log will show scans for `master` and `develop` branches, which have no `Jenkinsfile` so are skipped. The resulting view will show the `feature/jenkinsfile` job corresponding the only branch that currently has one. The build should run automatically.  2. The pipeline file is setup to only run `bake` & `deploy` stages when on `master` or `develop` branch. This is to provide us with very fast feedback for team members working on feature or bug fix branches. Each time someone commits or creates a new branch a basic build with testing occurs to give very rapid feedback to the team. Let's now update our `master` and `develop` branches to include the Jenkinsfile and delete the feature branch. @@ -149,10 +151,10 @@ git checkout feature/jenkinsfile ``` 2. Open up your `todolist-fe` application in your favourite editor and move to the `Jenkinsfile` in the root of the project. Update all `<YOUR_NAME>` and `<GIT_USERNAME>` as you did before, including in the prepare environment steps. Check the `GITLAB_DOMAIN` is set too. 2. Open up your `todolist-fe` application in your favourite editor and move to the `Jenkinsfile` in the root of the project. Update all `<YOUR_NAME>` and `<GIT_USERNAME>` as you did before, including in the prepare environment steps. Check the `GITLAB_DOMAIN` is set too.  2. Commit your changes to your feature branch as you did previously. 2. Commit your changes to your feature branch as you did previously. ```bash git add Jenkinsfile ``` @@ -193,7 +195,7 @@ 2. On Jenkins; create a new `Multibranch Pipeline` job called `todolist-fe`. 2. Add the `todolist-fe` git repository and set the credentials for git accordingly. 2. Add the `todolist-fe` git repository and set the credentials for git accordingly. 2. Set the trigger to scan every minute as done previously. Save the configuration and we should see the collection of Jobs as shown below.  @@ -224,7 +226,7 @@ ```  2. Use the OpenShift Applier to create the cluster content 2. Use the OpenShift Applier to create the cluster content ```bash cd .openshift-applier ``` @@ -267,7 +269,7 @@ NAME=todolist-api ``` 2. Use the OpenShift Applier to create the cluster content 2. Use the OpenShift Applier to create the cluster content ```bash cd todolist-api/.openshift-applier ``` @@ -296,9 +298,9 @@ #### 3a - OWASP ZAP > _OWASP ZAP (Zed Attack Proxy) is a free open source security tool used for finding security vulnerabilities in web applications._ 3. On your terminal; move to the `enablement-ci-cd` repo. We already have the `templates/jenkins-slave-generic-template.yml` template we're going to re-use from the previous lab so all we need is to check out the params file 3. On your terminal; move to the `enablement-ci-cd` repo. We need to checkout a template for OpenShift to build our Jenkins Slave images and some parameters for the `zap` slave. ```bash git checkout exercise4/zap-and-arachni params/jenkins-slave-zap git checkout exercise4/zap-and-arachni params/jenkins-slave-zap templates/jenkins-slave-generic-template.yml ``` 3. This should have created the following files which we will fill out. We will use a `ZAP` image hosted on the `rht-labs/ci-cd` repo so there will be no `Dockerfile` needed: @@ -322,15 +324,15 @@ -e "filter_tags=zap" ``` 3. Head to https://console.lader.rht-labs.com on Openshift and move to your ci-cd project > builds. You should see `jenkins-slave-zap` has been built. 3. Head to https://console.lader.rht-labs.com on OpenShift and move to your ci-cd project > builds. You should see `jenkins-slave-zap` has been built.  #### 3b - Arachni Scan > _Arachni is a feature-full, modular, high-performance Ruby framework aimed towards helping penetration testers and administrators evaluate the security of web applications._ 3. On your terminal; checkout the params and Docker file. The Dockerfile for the `Arachni` scanner is included here and we will point the build to it. 3. On your terminal; checkout the params and Docker file. The Dockerfile for the `Arachni` scanner is included here and we will point the build to it. ```bash git checkout exercise4/zap-and-arachni params/jenkins-slave-arachni docker/jenkins-slave-arachni git checkout exercise4/zap-and-arachni params/jenkins-slave-arachni docker/jenkins-slave-arachni ``` 3. Create an object in `inventory/host_vars/ci-cd-tooling.yml` called `jenkins-slave-arachni` with the following content: @@ -343,7 +345,7 @@ - arachni ``` 3. Update the `jenkins-slave-arachni` files `SOURCE_REPOSITORY_URL` to point to your gitlab's hosted version of the `enablement-ci-cd` repo. 3. Update the `jenkins-slave-arachni` files `SOURCE_REPOSITORY_URL` to point to your GitLab's hosted version of the `enablement-ci-cd` repo. ``` SOURCE_REPOSITORY_URL=https://gitlab.apps.lader.rht-labs.com/<GIT_USERNAME>/enablement-ci-cd.git SOURCE_CONTEXT_DIR=docker/jenkins-slave-arachni @@ -363,14 +365,14 @@ git push ``` 3. Run the ansible playbook filtering with tag `arachni` so only the arachni build pods are run. 3. Run the Ansible playbook filtering with tag `arachni` so only the arachni build pods are run. ```bash ansible-playbook apply.yml -e target=tools \ -i inventory/ \ -e "filter_tags=arachni" ``` 3. Head to https://console.lader.rht-labs.com on Openshift and move to your ci-cd project > builds. You should see `jenkins-slave-arachni`. 3. Head to https://console.lader.rht-labs.com on OpenShift and move to your ci-cd project > builds. You should see `jenkins-slave-arachni`.  _____ @@ -382,8 +384,8 @@ - Add the multi-branch configuration to the S2I to have Jenkins come alive with the `todolist-api` and `-fe` configuration cooked into it for future uses. Jenkins Pipeline Extension - Add an extension to the pipeline that promotes code to UAT environment once the master job has been successful. - Use a WAIT to allow for manual input to appove the promotion - Add an extension to the pipeline that promotes code to the UAT environment once the master job has been successful. - Use a WAIT to allow for manual input to approve the promotion Jenkins e2e extension (blue/green) - Add a step in the pipeline to only deploy to the `test` environment if the e2e tests have run successfully against which ever environment (blue or green) is not deployed. @@ -395,4 +397,4 @@ - [Intro](https://docs.google.com/presentation/d/1B3Fv4g66zZ8ZkqBq9TYmImJhUDvMecXCt4q3DXGWhjc/) - [Wrap-up](https://docs.google.com/presentation/d/1EOk6y798Xh1hsaQlxRuqyr23FIIf7sNY4any_yXIL7A/) - [All Material](https://drive.google.com/drive/folders/1oCjpl33Db7aPocmpu3NNF0B9czRvFq3m) - [All Material](https://drive.google.com/drive/folders/1oCjpl33Db7aPocmpu3NNF0B9czRvFq3m) exercises/5-non-functionals-strike-back/README.md
@@ -4,15 +4,15 @@  ## Exercise Intro Non functional testing provides valuable insights into code quality and application performance. Often overlooked but usually one of the most essential types of testing, non functional testing types can include, but are not limited to Non-functional testing provides valuable insights into code quality and application performance. Often overlooked but usually one of the most essential types of testing, non-functional testing types can include, but are not limited to - Performance Testing - Security testing - Static Code analysis - Vulnerability scanning There are many tools out there for supporting these testing types but often they are left to the end of a delivery. Many traditional projects will leave Performance testing or security sign off to a few weeks before Go Live. This raises the question of what do we do if things do not pass these tests? Do we hold off the Go Live or accept the risk. In most cases we can learn earlier if things will be show stoppers and more importantly we can automate them. There are many tools out there for supporting these testing types but often they are left to the end of a delivery. Many traditional projects will leave Performance testing or security sign off to a few weeks before Go Live. This raises the question of what do we do if things do not pass these tests? Do we hold off the Go Live or accept the risk? In most cases we can learn earlier if things will be show stoppers and more importantly we can automate them. For example; imagine a developer called `Sam` has checked in some poor performing function into an API that spikes it's response time. Let's call this `Sam Code`. This `Sam Code` may not be caught by our Unit Tests but could have very big impact on application usability. Before building code on top this and it becoming more of an issue at the end of a project; we could code and capture metrics around API response time and track these over time and hopefully spot regressions earlier. For example; imagine a developer called `Sam` has checked in some poorly performing function into an API that spikes its response time. Let's call this `Sam Code`. This `Sam Code` may not be caught by our Unit Tests but could have very big impact on application usability. Before building code on top this and it becoming more of an issue at the end of a project; we could code and capture metrics around API response time and track these over time and hopefully spot regressions earlier. Another one of the age old questions is "How do we know we're testing enough?". Well the simple answer is you can never do enough testing! But how do we know we are testing the right things? Code coverage metrics can be run on our application while running the tests. They can identify what files are being tested and a line by line of how many times a test executes against a block of code. Reporting these metrics in our pipeline gives a greater handle on the quality of our testing. @@ -45,7 +45,9 @@ 1. [stryker](http://stryker-mutator.io/) - Mutation testing! What is it? Bugs, or mutants, are automatically inserted into your production code. Your tests are run for each mutant. If your tests fail then the mutant is killed. If your tests passed, the mutant survived. The higher the percentage of mutants killed, the more effective your tests are. It's really that simple. ## Big Picture This exercise begins cluster containing blah blah > From the previous exercise; we introduced pipeline-as-code and new Jenkins Slave nodes. This exercise focuses on extending the pipeline with Non-functional testin and some automated security testing.  _____ @@ -63,15 +65,15 @@ ## Step by Step Instructions > This is a well structured guide with references to exact filenames and indications as to what should be done. ### Part 1 - Add Security scanning to the pipeline ### Part 1 - Add Security scanning to the pipeline > _In this exercise the first of our non-functional testing is explored in the form of some security scanning. We will add the scans to our Jenkinsfile and have them run as new stages_ 2. Open the `todolist-fe` application's `Jenkinsfile` in your favourite editor. The file is stored in the root of the project. 2. The file is layed out with a collection of stages that correspond to each part of our build as seen below. We will create a new stage to execute in parallel. 2. The file is laid out with a collection of stages that correspond to each part of our build as seen below. We will create a new stage to execute in parallel.  2. Create a new Parallel Stage called `security scanning` underneath the `stage("e2e test") { }` section as shown below. The contents of the `e2e test` have been removed for simplicity. 2. Create a new Parallel Stage called `security scanning` underneath the `stage("e2e test") { }` section as shown below. The contents of the `e2e test` have been removed for simplicity. ```groovy stage("e2e test") { // ... stuff in here .... @@ -122,7 +124,7 @@ } ``` 2. Finally add the reporting for Jenkins in `post` hook of our Declarative Pipeline. This is to report the findings of the scan in Jenkins as a HTML report. 2. Finally add the reporting for Jenkins in `post` hook of our Declarative Pipeline. This is to report the findings of the scan in Jenkins as an HTML report. ```groovy stage('OWASP Scan') { agent { @@ -218,7 +220,7 @@ 3. Coverage reports are already being generated as part of the tests. We can have Jenkins produce a HTML report showing in detail where our testing is lacking. Open the `todolist-fe` in your favourite editor. 3. Open the `Jenkinsfile` in the root of the project; move to the `stage("node-build"){ ... }` section. In the `post` section add a block for producing a `HTML` report as part of our builds. This is all that is needed for Jenkins to repor the coverage stats. 3. Open the `Jenkinsfile` in the root of the project; move to the `stage("node-build"){ ... }` section. In the `post` section add a block for producing a `HTML` report as part of our builds. This is all that is needed for Jenkins to report the coverage stats. ```groovy // Post can be used both on individual stages and for the entire build. post { @@ -237,7 +239,7 @@ } ``` 3. To get the linting working; we will add a new step to our `stage("node-build"){ }` section to lint the Javascript code. Continuing in the `Jenkinsfile`, After the `npm install`; add a command to run the linting. 3. To get the linting working; we will add a new step to our `stage("node-build"){ }` section to lint the JavaScript code. Continuing in the `Jenkinsfile`, After the `npm install`; add a command to run the linting. ```groovy echo '### Install deps ###' sh 'npm install' @@ -259,24 +261,24 @@ 3. When the build has completed; fix the linting errors if there are any and commit your changes. Look in Jenkins log for what the issue might be....  3. To view the coverage graph; go to the job's build page and open the `Code Coverage` report from the nav bar on the side. 3. To view the coverage graph; go to the job's build page and open the `Code Coverage` report from the nav bar on the side. <p class="tip"> NOTE - Sometimes this won't display on the `yourjenkins.com/job/todolist-fe/job/branch/` sidebar, click on an individual build in the build history and it should appear on the side navbar. </p>  3. Open the report to drill down into detail of where testing coverage could be improved! 3. Open the report to drill down into detail of where testing coverage could be improved!  <p class="tip"> NOTE - a good practice for teams is to try and increase the code coverage metrics over the life of a project. Teams will often start low and use practices such as retrospective to increase the quality at specific times. NOTE - a good practice for teams is to try and increase the code coverage metrics over the life of a project. Teams will often start low and use practices such as retrospective to increase the quality at specific times. </p> 3. (Optional Step) - Install the Checkstyle plugin; and add `checkstyle pattern: 'eslint-report.xml'` below the `publishHTML` block to add reporting to Jenkins! ### Part 3 - Nightly light performance testing > _In this exercise, we will execute the light performance tasks in our API to collect data about throughtput time in hopes if the API ever has some `Sam` quality code checked in, we will spot it_ > _In this exercise, we will execute the light performance tasks in our API to collect data about throughput time in hopes if the API ever has some `Sam` quality code checked in, we will spot it_ An arbitrary value for the API's to respond in has been chosen. It is set in the `todolist-api/tasks/perf-test.js` file. In this exercise we will get Jenkins to execute the tests and fail based on the score set there! An arbitrary value for the APIs to respond in has been chosen. It is set in the `todolist-api/tasks/perf-test.js` file. In this exercise we will get Jenkins to execute the tests and fail based on the score set there! 4. Create a new Item on Jenkins, `nightly-perf-test` and make it a freestyle job.  @@ -307,7 +309,7 @@ 4. On the Post Build actions section we will plot the data from the perf tests in Jenkins. Add a `Post-build Action > Plot Build Data`. 4. On the new dialog, name the Plot group eg `benchmark-tests` and add `create-api` as the Plot title. Set the `Number of Builds to Include` to a large number like `100`. Set the Data Series file to be `reports/server/perf/create-perf-score.csv` and mark the `Load data from CSV fiel` checkbox. Apply those changes 4. On the new dialog, name the Plot group e.g. `benchmark-tests` and add `create-api` as the Plot title. Set the `Number of Builds to Include` to a large number like `100`. Set the Data Series file to be `reports/server/perf/create-perf-score.csv` and mark the `Load data from CSV field` checkbox. Apply those changes  4. Hit `Add Plot` to add another. Set Plot group to `benchmark-tests` again but this time setting the Plot title to `show-api`. Set the Data Series file to be `reports/server/perf/show-perf-score.csv` and mark the `Load data from CSV` radio button. Save those changes and run the job (Job could take a while to execute!). @@ -334,4 +336,4 @@ - [Intro](https://docs.google.com/presentation/d/1YQ0hUV3o7DW8O40SiI-BQZXCOSVeQGjo2iTxCL2GZfk/) - [Wrap-up](https://docs.google.com/presentation/d/102hRHDlC9PUIsMs3m1fZy8QUaB5UKzBlhBPdehRWw38/) - [All Material](https://drive.google.com/drive/folders/1seT0V3ABHNonvtFvORNt836NgSeYPuWW) - [All Material](https://drive.google.com/drive/folders/1seT0V3ABHNonvtFvORNt836NgSeYPuWW) exercises/6-return-of-the-app-monitoring/README.md
@@ -32,12 +32,14 @@ 1. [Pipeline Aggregator View](https://wiki.jenkins.io/display/JENKINS/Pipeline+Aggregator+View) - Allows the users to view the history of their pipelines with stage information (failed/In Progress/Passed) and the changes monitored) ## Big Picture This exercise begins cluster containing blah blah > From the previous exercise; we introduced non-functional testing to our pipeline. This exercise focuses on radiation of useful information such as build stats and times from our pipeline.  _____ ## 10,000 Ft View > The goal of this exercise is to introduce Build Monitors to radiate teams progress on Dashboards. > The goal of this exercise is to introduce Build Monitors to radiate team's progress on Dashboards. 2. Create a new Dashboard for our Builds using the plugin above. Use Regex to add jobs to it. Use the BuildFail Analyser to add meaningful data to the reason for failures. @@ -60,7 +62,7 @@ 2. Check the box to use Regular Expression and set the value to be something that should scrape our apps such as `.*todolist.*`  2. Finally; select `Display committers` and set the Failure Analyser to `Description`. This allows us to write regex for when fails occur in Jenkins and have the reasons plotted on the graph. For example; number of test scores or common compilation errors. 2. Finally; select `Display committers` and set the Failure Analyser to `Description`. This allows us to write regexes for when failures occur in Jenkins and have the reasons plotted on the graph. For example; number of test scores or common compilation errors.  2. Save your configuration to see your Build Monitor! @@ -121,7 +123,7 @@ ```  2. We can save up these regex and inject them into the `jenkins-s2i` so the configuration is there the next time we launch and we don't have to code them up again. In `enablement-ci-cd` repo; the `jenkins-s2i/configuration/build-failure-analyzer.xml` already contains ones we've collected on previous residencies. 2. We can save up these regexes and inject them into the `jenkins-s2i` so the configuration is there the next time we launch and we don't have to code them up again. In `enablement-ci-cd` repo; the `jenkins-s2i/configuration/build-failure-analyzer.xml` already contains ones we've collected on previous residencies. ### Part 3 - Seed Jenkins Dashboards > _TODO - Add instructions for creating dashboards as part of s2i in Jenkins setup using DSL_ @@ -137,7 +139,7 @@ - Add `Slack` integration to the Pipeline by setting up a WebHook to call the slack endpoint with Build Stats - Add `Twillio` text integration to send you text messages when the build fails. Additional Monitoring - Explore the Application's FEK stack inside OpenShift - Explore the Application's EFK stack inside OpenShift ## Additional Reading > List of links or other reading that might be of use / reference for the exercise exercises/7-the-cluster-awakens/README.md
@@ -1,6 +1,6 @@ # The Cluster Awakens > In this exercise; we will monitor the core of the OpenShift Cluster. Watch for spikes in memory usage, harddisk space and other cluster stats. > In this exercise; we will monitor the core of the OpenShift Cluster. Watch for spikes in memory usage, hard disk space and other cluster stats.  @@ -8,7 +8,7 @@ ## Learning Outcomes As a learner you will be able to - View vital stats about the clusters health using Prometheus queries - View vital stats about the clusters health using Prometheus queries - Visualise the data on Grafana dashboards - Overlay log messages to the Grafana dashboards creating a very short feedback loop for Ops and Dev teams. @@ -19,7 +19,9 @@ 1. [Grafana](https://grafana.com/) - The analytics platform for all your metrics Grafana allows you to query, visualize, alert on and understand your metrics no matter where they are stored. Create, explore, and share dashboards with your team and foster a data driven culture. Trusted and loved by the community. ## Big Picture This exercise adds no new components to the big picture > From the previous exercise; we introduced app and jenkins monitoring. This exercise focuses on radiation of cluster statistics using Prometheus to scrape metrics and Grafana to display them.  _____ @@ -43,4 +45,4 @@ - [Intro](https://docs.google.com/presentation/d/179Bz9GzHIcDxwb4RxxlQUESfqES4hArU1puGUjkAOoI/) - [Wrap-up](https://docs.google.com/presentation/d/1n6f_A3i5019lZYmCBNhl9O-S3xxjpHDT5I7ZoCqYyHo/) - [All Material](https://drive.google.com/drive/folders/13YIiKuzBmr9mGzg4bsEns5yVWx_Zc8Hs) - [All Material](https://drive.google.com/drive/folders/13YIiKuzBmr9mGzg4bsEns5yVWx_Zc8Hs) exercises/8-the-last-unicorn-dev/README.md
@@ -10,10 +10,10 @@ _____ ## Learning Outcomes As a learner you will be able to identify what a an amazing Demo Day consists of! - Identify key success factors for a facilitating Demo Day As a learner you will be able to identify what an amazing Demo Day consists of! - Identify key success factors for facilitating a Demo Day - Run Demo Day as part of the class room activities - Identify the success factors and antipatterns in making Labs Engagements work wit our clients - Identify the success factors and antipatterns in making Labs Engagements work with our clients _____ @@ -21,4 +21,4 @@ - [Intro](https://docs.google.com/presentation/d/1XW_k9LYEcA4yk46GvN5yWih545gKUNeQW4-5GF9jYDg/) - [Wrap-up](https://docs.google.com/presentation/d/1veO6Q7yG1Kmy-3GfjZnGlsQ7NOXTyRBiYJWMA8y3CEE/) - [All Material](https://drive.google.com/drive/folders/1TmpX5uCwzfsZfFHNlXXZZ4r6wiMDDO4i) - [All Material](https://drive.google.com/drive/folders/1TmpX5uCwzfsZfFHNlXXZZ4r6wiMDDO4i) exercises/README.md
@@ -1,28 +1,37 @@ # Enablement Material > Red Hat Open Innovation Labs Enablement Material. # DevOps Culture & Practice > Red Hat Open Innovation Labs Enablement Material. Preparing Engineers, consultants and TSMs with all the cultural and engineering practices for life in a Residency.  This is a collection of practices and exercises to take a learner through a four day simulated residency experience. Learners can expect to be exposed to labs practices such as [Event Storming](https://rht-labs.github.io/practice-library/practices/event-storming/), [Social Contract](https://rht-labs.github.io/practice-library/practices/social-contract/) and [Impact Mapping](https://rht-labs.github.io/practice-library/practices/impact-mapping/) amoung many more which can be found in our [Practice Library](https://rht-labs.github.io/practice-library/). Learners will also be exposed to `Labs CI/CD` - how we use OpenShift & Ansible in conjunction with Jenkins to automate build and deploy of a sample todolist application and it's required infrastructure. This is a collection of practices and exercises to take a learner through a four day simulated residency experience. Learners can expect to be exposed to labs practices such as [Event Storming](https://rht-labs.github.io/practice-library/practices/event-storming/), [Social Contract](https://rht-labs.github.io/practice-library/practices/social-contract/) and [Impact Mapping](https://rht-labs.github.io/practice-library/practices/impact-mapping/) among many more which can be found in our [Practice Library](https://rht-labs.github.io/practice-library/). Learners will also be exposed to `Labs CI/CD` - how we use OpenShift & Ansible in conjunction with Jenkins to automate build and deploy of a sample todolist application and its required infrastructure. ## Learner Outcomes 1. Prepare participants to *jointly* deliver on upcoming Labs Residencies - specifically: senior consultants, architects, and agile PMs 2. Explore all principle practices used in a residency through a hands on real life experience 3. Enable countries and regions to run the session independently ## Learner pre-requisites - OCP CLI v3.9 - Ansible v2.5 - NodeJS v8.x - Git Installed - Google Chrome Web Browser (>59) - Docker latest - Access to an OpenShift cluster `oc login -u <username> -p <password> <cluster_url>` - Text editor such as Atom, IntelliJ or Visual Studio Code (The exercise were created using VSCode, so the screenshots will match it's layout and colour schemes) | Software | Version | Check | | -------- | ------- | ----- | | OCP CLI | v3.9 | $ oc version | grep -i --color oc <br><span style="color:red">oc </span> v3.9.0+191fece | | Ansible | v2.5 | $ ansible --version | grep -i --color ansible <br> <span style="color:red">ansible</span> 2.5.5 <br> .... <br>| | NodeJS | v8.x | $ node -v <br> v8.11.3| | Git Installed | | $ git --version <br> git version 2.17.1| | Google Chrome Web Browser | (>59) | click [here](chrome://version/) if Google Chrome is your default browser else copy the link `chrome://version/` in your Chome | | Docker latest | Community Edition - Edge | $ docker --version <br> Docker version 18.05.0-ce, build f150324| | JDK | v8 | $ java -version <br>java version "1.8.0_131"<br>Java(TM) SE Runtime Environment (build 1.8.0_131-b11)<br>Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)| | Access to an OpenShift cluster | | `oc login -u <username> -p <password> <cluster_url>` | | Text editor such as Atom, IntelliJ or Visual Studio Code <br><br> (The exercises were created using `VSCode`, so the screenshots will match its layout and colour schemes) | - | - | > (TODO) Download the tools-container containing required Ansible and OpenShift tooling pre-installed ______ ## Git and Containers 101 - Git tutorial covering the basics - https://try.github.io/ - Handy guide for those new to containers - https://developers.redhat.com/blog/2018/02/22/container-terminology-practical-introduction/ ## Setup your IDE If you are using VSCode; some handy plugins that will make the lessons easier are: If you are using VSCode, Atom, Eclipse, IntelliJ or some other IDE that supports Plugins; some handy ones that will make the labs easier are: - YAML Syntax Highlighter - Autosave - Autosave - JavaScript Syntax Highlighter - Vue.js - Eslint exercises/_sidebar.md
@@ -1,4 +1,5 @@ * [Home](/) * [The Practices](the-practices/README.md) * [1. The Manual Menace](1-the-manual-menace/README.md) * [2. Attack of the Pipelines](2-attack-of-the-pipelines/README.md) * [3. Revenge of the Automated Testing](3-revenge-of-the-automated-testing/README.md) @@ -7,4 +8,4 @@ * [6. Return of the Monitoring](6-return-of-the-app-monitoring/README.md) * [7. The Cluster Awakens](7-the-cluster-awakens/README.md) * [8. The Last Unicorn Dev](8-the-last-unicorn-dev/README.md) * [0. Rogue Cluster: A Setup Guide](0-rogue-cluster/README.md) * [Rogue Cluster: A Setup Guide](0-rogue-cluster/README.md) exercises/custom.css
@@ -5,3 +5,5 @@ content: "!"; background-color: #f66; } /* iframe { height: -webkit-fill-available; } */ exercises/exercise-layout-template/README.md
@@ -1,6 +1,6 @@ # Exercise Title > Short description of the exercise and it's outcomes > Short description of the exercise and its outcomes _____ ## Learning Outcomes @@ -57,4 +57,4 @@ > List of links or other reading that might be of use / reference for the exercise ## Slide links > link back to the deck for the supporting material > link back to the deck for the supporting material exercises/images/big-picture/big-picture-1.jpg
@@ -32,6 +32,13 @@ <script src="//unpkg.com/prismjs/components/prism-groovy.min.js"></script> <script src="//unpkg.com/prismjs/components/prism-yaml.min.js"></script> <script src="//unpkg.com/prismjs/components/prism-json.min.js"></script> <script> // this didn't work cuz of CORS :( function resizeIframeHack(iframe) { // console.log(window.document.body.scrollHeight) iframe.height = iframe.contentWindow.document.body.scrollHeight + "px"; } </script> </body> </html> exercises/the-practices/README.md
New file @@ -0,0 +1,39 @@ # The Practices > A Large number of practices are used throughout this course. [The Open Practice Library]() contains all of the practices used on an Open Innovation Lab Residency. Below is a section of the ones used in this course. _____ ## Visualisation of Work [visualisation-of-work](https://rht-labs.github.io/practice-library/practices/visualisation-of-work/ ':include :type=iframe width=100% height=3974px scrolling=no') ## Team Sentiment [team-sentiment](https://rht-labs.github.io/practice-library/practices/team-sentiment/ ':include :type=iframe width=100% height=2405px scrolling=no') ## Burn Down [burndown](https://rht-labs.github.io/practice-library/practices/burndown/ ':include :type=iframe width=100% height=3179px scrolling=no') ## Realtime Retro [realtime-retro](https://rht-labs.github.io/practice-library/practices/realtime-retrospective/ ':include :type=iframe width=100% height=2690px scrolling=no') ## Stop the World Event [stop-the-world](https://rht-labs.github.io/practice-library/practices/stop-the-world-event/ ':include :type=iframe width=100% height=2081px scrolling=no') ## Social Contract [social-contract](https://rht-labs.github.io/practice-library/practices/social-contract/ ':include :type=iframe width=100% height=2324px scrolling=no') ## Impact Mapping [impact-mapping](https://rht-labs.github.io/practice-library/practices/impact-mapping/ ':include :type=iframe width=100% height=3383px scrolling=no') ## Value Stream / Metrics Based Process Mapping <!-- <iframe src="https://rht-labs.github.io/practice-library/practices/vsm-and-mbpm" allowfullscreen scrolling="no" onload="resizeIframeHack(this)"> </iframe> --> [vsm-and-mbpm](https://rht-labs.github.io/practice-library/practices/vsm-and-mbpm/ ':include :type=iframe width=100% height=3551px scrolling=no sandbox') ## Event Storming [event-storming](https://rht-labs.github.io/practice-library/practices/event-storming/ ':include :type=iframe width=100% height=3275px scrolling=no') ## User Story Mapping [user-story-mapping](https://rht-labs.github.io/practice-library/practices/user-story-mapping/ ':include :type=iframe width=100% height=2843px scrolling=no') facilitation/00-setup/README.md
@@ -16,6 +16,7 @@ * Ability to play sound from laptop * Strong WiFi (all delegates will need to be connected throughout the Enablement) * At least one break out area - ideally a small room near the main room * Pair programming - Monitors for the tables. One between two attendees (or mobs up to three). ## Shopping / Bring List @@ -27,6 +28,7 @@ * Henrik Kniberg Skateboard Picture * The Agile Manifesto Values and Principles * What DevOps is Not * The Agile Principles cartoon from Knowledge Train * Some spare adapters for overseas' participants to connect laptops to power * Bluetac * A1 Sticky Chart Paper @@ -40,6 +42,9 @@ * Fun activities (e.g. a mini golf set and mini ping pong set) * Option to project build monitors (e.g. through Rasperry Pis) - organise extra monitors or bring projector * Think about capturing the Enablement by bringing, for example, GoPro Camera, 360 cameera, etc. * Monitors for pairing if not provided by the venue * Download all videos used in the training incase of WiFi connectivity issues * Order some Swag from Marketing - great for everyone to take something away and it also provides an opportunity to boost Team Identity and get a great photo with everyone in, for example, their new t-shirt! ## Setting up the Room @@ -56,6 +61,12 @@ * Labs is…. * Space for Faces * Space for Animals * End of Day 2 Retrospective canvas (one for each table group) * End of Day 3 Retrospective canvas (one for the whole group) * A location for catering to be delivered to and consumed from We strongly recommend using the full day before the Enablement to set the room up as you expect it to be used during the 4 days (including putting up all the "Big Picture" and "Practice Corner" as you expect it to be on day 4). Not only does this help familiarise further with the material but it will also test the space considerations. We then "re-set" the space to start the Enablement with just a circle of chairs. This facilitates a great collaborative start and also provide the opportunities for the newly formed teams to configure their space themselves. Think about the wall space that will be used for: * Team's Social Contract @@ -64,11 +75,30 @@ * Metric Based Process Maps * Value Slicing * End of Day Retros * Pairing and mob faces * Andon Chord or Real Bell / Buzzer if available * The example linkage for ToDoIst: Impact Map -> Event Storm -> Value Slices -> Initial Product Backlog -> Sprint 1 Board (done) -> Updated Product Backlog -> Sprint 2 Board (which is the focus on Exercise 3) ## Facilitation Guidelines * Facilitation Guides have been prepared for each of the exercises (technical and non-technical). These are intended to be living and breathing documents which will be updated as more Enablement sessions are run. * Slideware includes lots of real world residency examples of practices being taught. It is expected that these examples will change session-by-session and the Labs facilitators will inject their own stories, photos and videos in here. * Catering is an important factor to consider. Having group breakfasts and lunch emulates what we do on Residencies * Having a group social during the week is also an important aspect of the Enablement * Catering is an important factor to consider. Having group breakfasts and lunch emulates what we do on Residencies and provides additional time to bond, network, form teams, relax and have fun / chill-out time * Having a group social during the week is also an important aspect of the Enablement and representative of what we try to do during Residencies. Provides similar impact to point above and helps drive team culture. * It is strongly recommended to plan for classes of up to 24 people. This will require an "overall facilitator" (to focus on opening / closing the workshop and each day) and one "technical facilitator" (people who can trouble-shoot technical issues and are very familiar with the technical exercises) for every 12 participants. So, a full group of 24 participants would need 1 overall facilitator and 2 technical facilitators. The facilitation of this is intense and demanding and required 100% focus during the week. * For growing the facilitation pool, we strongly recommend a three stage approach * Attend and complete the Enablement in full as a participant * Attend a subsequent Enablement again but shadow the Facilitator team with some opportunities to present * Be a primary facilitator on a subsequent Enablement * Each day should include a "walk the walls" exercise to introduce and re-visit 1) The Product Backlog/Burndwon; 2) The Big Picture; and 3) The Practice Corner. We often start each morning with this and allow as much time as possible for discussion, questions and to kick-start the day with collaboration * We like to include a thought-inspiring YouTube video each day. They are nice to play first thing (before the Walk the Walls) as people come in and are having coffee. Equally, they are good to be used as time dividers, breaking up long exercises, just after lunch, etc. Videos that have beeen used to date include: * [Henrik Kniberg's Product Ownership in a Nutshell](https://youtu.be/502ILHjX9EE) * [Drive: The surprising truth about what motivates us](https://youtu.be/u6XAPnuFjJc) * [Django explaining DevOps in a Bath](https://youtu.be/Qj09XRhp0lA) * ["Greatness" by David Marquet](https://youtu.be/OqmdLcyES_Q) * We like to play some fun games / energisers during the four days. It helps drive fun and team culture as well as keep enegery levels up (especially useful during the longer technical exercises). Activities we have used include: * [Human Rock Paper Scissors](http://www.funretrospectives.com/human-rock-paper-scissors/) * [Collaborative Face Drawing](http://www.funretrospectives.com/collaborative-face-drawing/) * [Context Switching Game](http://personalkanban.com/pk/expert/context-switching-why-limit-your-wip-iv/) * Add a channel to the [Enablement Slack Group](labsenablement.slack.com) specifically for your session and add all participants and facilitators. This is great for promoting discussion before, during and after the workshop. facilitation/01-kick-off-and-target-outcomes/README.md
@@ -12,14 +12,17 @@ ## Facilitation Materials Needed * Teams in table size of 4 to 6 * Sticky Notes - rectangular size on each table * Sharpie Pens (1 per person) on each table * Start session with the whole group in a big circle * Group should be near the information radiators used during the session (Backlog, Big Picture, Realtime reto, etc.) * Sticky Notes - one large (A5) sticky note on each chair (for Faces) and one smaller rectangular sticky note (for Animals) on each chair. One small square Red sticky and one small square Green sticky (for mood marbles) on each chair * Sharpie Pens - one on each chair ## Facilitation Guidelines * Presentation of the slides * Early ice breaker activity (provided in slides) * Play the [Collaborative Face Drawaing](http://www.funretrospectives.com/collaborative-face-drawing/) energizer * Present slides which sign posts to all the introductions to make * Showcase of the room to point to the visual artefacts to be used as a part of running the session (sign posted in slides) * When introducing the Backlog for the 4 days, it's important to note that we almost certainly will not do everything on the backlog. We will also embrace feedback and change and may well add, remove, update, re-order the items on it. This is an important lesson that Backlogs never get done completely! * Round the room for everyone to introduce themselve facilitation/02-social-contract/README.md
@@ -12,7 +12,7 @@ ## Facilitation Materials Needed * Teams in table size of 4 to 6 * Start as one big group. During this sessio, teams will form into groups of 4 to 6 * Sticky Notes - large (A5) sized of different colors * Sharpie Pens (1 per person) on each table * Flip-chart or Magic Whiteboard paper @@ -26,6 +26,8 @@ * Present the slides to introduce Social Contracting, what it is, why we use it and share some Labs stories * Present the residency examples provided in slides and encourage any Labs people present to talk about their experiences of using the practice * Kick off the interactive exercise: * Get the whole group to self-organise into a straight line in order of technical experience. * Divide the group as evenly as possible (no more than 6 per table) so there is a spread of technical experience in each table * In table groups, take the opportunity to (once again) say hello to each other * Talk about how they want to work with each other this week and capture key behaviours on large sticky notes to form the social contract * Encourage everyone to sign their social contract @@ -33,4 +35,5 @@ * Encourage each table to use one of the recordable buttons to record their team noise (to help with the cultural and fun aspects we want to inject into the atmosphere throughout this enablement) * Overall group Social Contract * Have each group playback key points in their Social Contract and call out any that they would like applicable to the whole group. One of the the facilitators should capture these as a Group Social Contract * Encourage a consensus on the times to take for breaks / lunches up front. * Again, encourage everyone to sign the big group Social Contract facilitation/03-what-is-labs/README.md
@@ -23,4 +23,5 @@ * Early interactive acitivty to get each participant to think and write down what Labs is * Presentation of the slides * Show short Labs promotion video * Show short Labs promotion video * This session may generate lots of questions and kick-start discussions. This is a great opportunity to use the car park / parking lot if you think the answers will naturally emerge during the 4 days. facilitation/04-retrospectives/README.md
@@ -29,8 +29,8 @@ * Make sticky notes and sharpies available near the timeline * Introduce the real-time retrospective early on the first day and encourage people to add to it as and when they experience something positive or negative or would like to feedback something positive or negative * Each day should also finish with a retrospective. It's up the the facilitators to use whatever exercise they would like to. It is recommended to try some different flavors rather than finish with exactly the same exercise each day. Some examples include: * Day 1 - a round the group impact feedback (say one thing that impacted you) * Day 2 - a stop/start/continue retro * Day 1 - a round the group impact feedback (say one thing that impacted you. Pass the ball; you can only talk if you have the ball. * Day 2 - Individual table retros. Allow teams to feedback against each other's committment to the social contract. Use a stop/start/continue retro to facilitate the conversation. Collect Key points onto group wide retro board. * Day 3 - a do more of / do less of / continue / stop / start retro * Day 4 - a timeline retro * Day 4 - a fist of 5 confidence vote. Facilitator should ask how confident everyone is in jointly delivering and upcoming Labs residency (as per the target outcome of this Enablement). Everyone should simultaneously announce a score of 0-5 using fingers. The same question can be asked as to how much everyone would like to participate in a Labs residency. * Each retrospective should be introduced by one of the facilitators, have a time boxed period for individuals to add their input and a group alignment / discuss to identify clusters / themes and corrective actions facilitation/06-event-storming/README.md
@@ -30,11 +30,10 @@ ## Facilitation Guidelines * Present the slides to introduce Event Storming, what it is, why we use it and walk through the steps in how to use it * Present the residency examples provided in slides and encourage any Labs people present to talk about their experiences of using the practice * Present the residency examples provided in slides and encourage any Labs people present to talk about their experiences of using the practice. We have found presenting a real Event Storm (ideally with the physical board) is much more effective than presenting the slides and has resulted in much better conversation. If you have access to real artefacts, consider reducing the slides. * Kick off the interactive exercise: * As a class, put up the pre-baked Event Storm. The Facilitator should talk through as he/she puts up the events, commands, user, external system, etc.  * Table groups should then replicate the pre-baked event storm artifact and follow the instructions in the slide to extend this to cover additional functionality. Some examples have been given. You could also encourage participants to think about their own experience of to-do-list management * Time box of 20 minutes. Facilitators should walk round the room and help with any questions and engage in conversations * As a class, talk about aggregates and what aggregates might apply to these emerging event storms * * As a class, talk about aggregates and what aggregates might apply to these emerging event storms facilitation/08-vsm-and-mbpm/README.md
@@ -12,6 +12,9 @@ ## Facilitation Materials Needed * Pennies or poker chips (20 for each table) * Flipchart paper - one piece for each table * Marker pens * Teams in table size of 4 to 6 * Sticky Notes - set of the following on each table * Small Rectangular - lots of one color @@ -22,8 +25,9 @@ ## Facilitation Guidelines * Present the slides to introduce Value Stream Mapping and Metrics Based Process Mapping, what they are and why we use them * Kick off the interactive exercise: * Play the [Penny Flow game](https://www.leanagiletraining.com/better-agile/agile-penny-game-rules/) to introduce the notion of capturing metrics around flow (and the impact batch size has). * Present the slides to introduce Value Stream Mapping and Metrics Based Process Mapping, what they are and why we use them. Show some real world examples and talk through the MBPM before and after as well as the roll-up of metric improvements. * Optiopnnaly, run a further interactive exercise (with the addition of the Penny Flow Game and the feedback before and after including this, this exercise is less valuable): * In pairs, capture all business processes between the trigger of the business requesting a feature and the outcome of that feature running in production and being used * In groups of 12, combine all processes onto a single map * Add some metrics based on traditional software development (with minimal automation) - Process Time, Lead TIme, CAC% facilitation/09-intro-to-agile/README.md
@@ -9,6 +9,8 @@ The latest version of slides for the session are available [here](https://docs.google.com/presentation/d/1eYI04ChApbQd-a1b8GsBaRfGzuIm12AxYyi61fEE9G4/edit?usp=sharing) * If possible; bring in boards showing Burn down, feature & task level breakdown, estimation ladders etc * Download the Henrick Video for offline playing incase of WiFi issues. ## Facilitation Materials Needed Binary files differ
facilitation/100-big-picture-and-dinosaur/complete-big-picture.jpg
New file @@ -0,0 +1,31 @@ # Pairing and Mobbing > Session to introduce the practices of Mob Learning and Pair Programming, how we use them and show some examples mobbing and pairing in action. This will also include facilitating a short exercise to practice pairing and mobbing in a fun way! We use this session to strongly position pairing as a mechanism for the group completing the technical exercises of this Enablement. This is very important in achieving the target outcome of the Enablement and the Definition of Done. _____ ## Slides The latest version of slides for the session are available [here](https://docs.google.com/presentation/d/1FQ16TPWh3IrSnG97baaE1Tace9XV7p0uu0MdQuOdMZ4/edit?usp=sharing) ## Facilitation Materials Needed * Table groups of 4-6 people * Monitors and keyboards - one per pair * Sticky notes - one small square per person, one large (A5) per pair, one big flip-chart page per table * Sharpie pens and markers * Wall space to display drawings ## Facilitation Guidelines * Present the slides to introduce Pairing and Mobbing, what they are, why we use them and show some examples. A YouTube video of Mob Programming is included in the deck and is useful to talk over as a group * Present the residency examples provided in slides and encourage any Labs people present to talk about their experiences of using the practice * Kick off [Pair Drawing exercise](https://www.industriallogic.com/blog/pairdraw-2/) and, for fun, extend to Mob Draw. * Provide strong direction to the class that we want everyone to pair (or mob in 3 if uneven table size) during all the exercises to get experience of these practices. Explain that this allows more techie people some time to practice their coaching and explanation skills (something we need to do regularly with business stakeholders in residencies) and allows the less techie people to get a little hands-on with these very important engineering practices. Based on experience of the initial Enablement sessions, this discussion and positioning is very important. * If monitors have not yet been set up on the tables, now is a good time to bring them in and set them up. facilitation/99-wrap-up/README.md
New file @@ -0,0 +1,42 @@ # Wrap up and Post Enablement Activities > Final session to wrap up the 4 day Enablement. _____ ## Slides The latest version of slides for the session are available [here](https://docs.google.com/presentation/d/1veO6Q7yG1Kmy-3GfjZnGlsQ7NOXTyRBiYJWMA8y3CEE/edit?usp=sharing) ## Facilitation Materials Needed * An open space for the whole group to form a large circle ## Facilitation Guidelines * If time has permitted to produce a short summary video or a slide deck of photos from the 4 days, show that now (it's a great visual way to reflect and summarise the week) * If not done already, get a group photo of everyone * Present slides with summary of all the practices we've introduced during the four days * Show the links to the material we have open sourced including: * Enablement Docs * Labs CI/CD * Open Practice Library * Labs Book Library * Run the Confidence Voting retrospective as described in the Retrospectives facilitation guide * Encourage final updates of the Real Time Retrospective and also mention a post Enablement survey will be issued * Go round the circle for some final impact feedback from each participant * Have a final ritual of high fives before closing ## Post Facilitation * Photograph everything on walls, tables, boards, etc. and add to the media store that has hopefully grown during the week * Send a wrap-up e-mail to everyone with links to repos, photos, videos shown, etc. Example [here](https://drive.google.com/open?id=1ljFJxYId0Sj7_zzXuNSTjU_g5BVB9bOC7NQ-xltAouo) * Issue a survey. Example [here](https://drive.google.com/open?id=1pb-QuaGkcjsMji1H3RZ46VMXj3wAXBnuXH6lWYs7-u8) and encourage completion via e-mail, Slack, etc. * After a week or so collate feedback responses into a summary. Example [here](https://drive.google.com/open?id=114fYkT3Tk1a98jmfJLunQpaoZLogtGXRKCmK-2SIZX8) * Consider further feedback in a few months to assess success against the original target outcomes. * Add everyone to the the Alumni channel in Slack










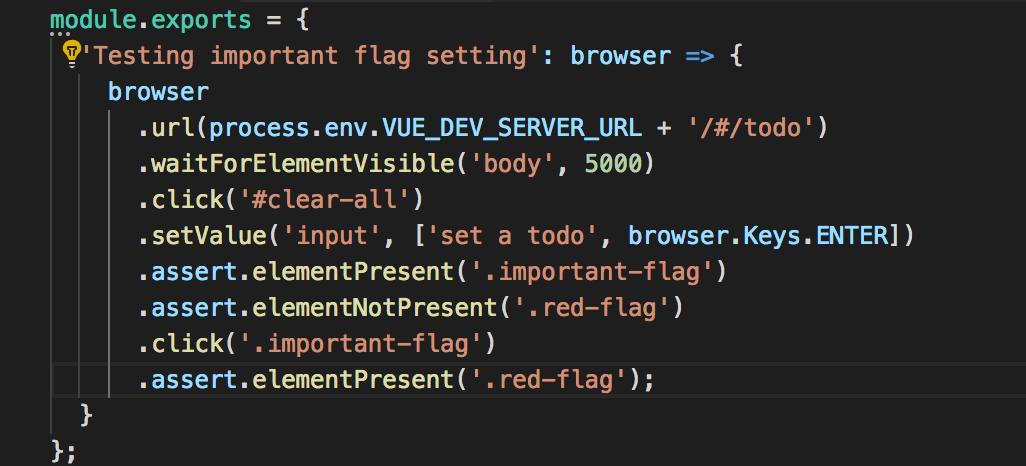

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}